
Le contexte : un gadget IA à 169 €
Il y a quelques mois, j’ai cédé à la curiosité et j’ai commandé sur Amazon un Plaud NotePin S — un petit enregistreur vocal IA qui tient dans la poche et qui promet de transformer n’importe quelle réunion en compte-rendu structuré. Le truc est plutôt bien fichu : tu cliques pour enregistrer, l’audio est envoyé sur leur cloud, et quelques minutes plus tard tu reçois un résumé propre dans leur app.
- Le contexte : un gadget IA à 169 €
- Architecture générale
- Côté Azure : les ressources à provisionner
- La brique centrale : Azure Speech Batch API
- Étape 1 : uploader l’audio sur Azure Blob Storage
- Étape 2 : créer un job de transcription
- Étape 3 : récupérer la transcription quand elle est prête
- Étape 4 : générer le compte-rendu avec Claude
- Étape 5 : envoyer le résultat par email
- Le pattern async fire-and-forget
- Déploiement sur Azure Web App
- Bilan et coût
- Voir le projet sur GitHub

Sympa, mais en utilisant l’objet quelques semaines, je me suis posé deux questions :
- Pourquoi avoir besoin d’un device dédié ? Mon smartphone a un dictaphone tout à fait correct. Une app Android idem.
- Qu’est-ce qu’il y a vraiment derrière ? Du speech-to-text + un LLM qui résume. Soit grosso modo deux APIs que je connais bien.
Du coup le défi de soirée était posé : recréer le comportement du Plaud NotePin avec les briques Azure, histoire de mieux comprendre ce qu’il y a sous le capot — et accessoirement, de découvrir Azure Speech, un produit Microsoft que je n’avais jamais eu l’occasion de mettre en pratique.
C’est exactement ce que je vous propose de faire ici, étape par étape. On va construire une web app qui :
- Reçoit un fichier audio (n’importe quel enregistrement de téléphone)
- Le transcrit via Azure Speech-to-Text Batch API
- Génère un compte-rendu structuré avec Claude (Anthropic)
- L’envoie par email à l’utilisateur
Volontairement, j’ai réutilisé du CSS aux couleurs de mon employeur et Claude m’a aidé à rendre ça graphiquement sexy (car oui je suis ultra mauvais en design).
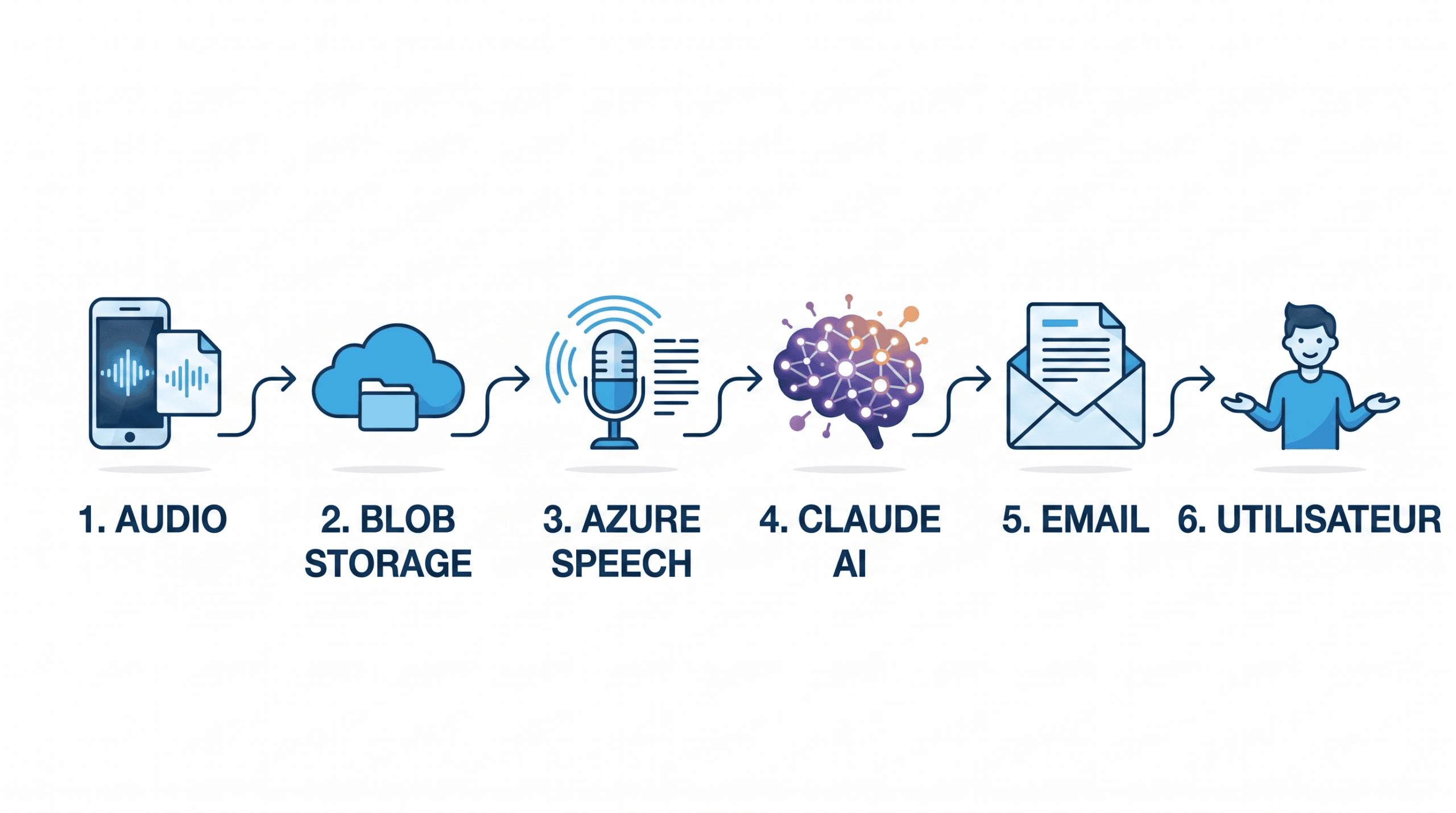
Architecture générale
Avant le code, voici la logique de ce que nous souhaitons mettre en place :
Utilisateur (navigateur)
│ upload audio + email + type de CR
▼
Azure Web App (Node.js, container)
│
├──→ Azure Blob Storage (stockage temporaire de l'audio)
├──→ Azure Speech Batch API (transcription async)
├──→ Claude API (génération du CR structuré)
└──→ Brevo API (envoi du CR par email)
Le flux est volontairement asynchrone : l’utilisateur dépose son fichier, l’app lui dit « c’est parti, vous recevrez le résultat par email », et le traitement continue en arrière-plan pendant 10 à 20 minutes selon la durée de l’audio. Pas de barre de progression à regarder, pas de timeout côté navigateur. C’est exactement le comportement du Plaud.
Côté Azure : les ressources à provisionner
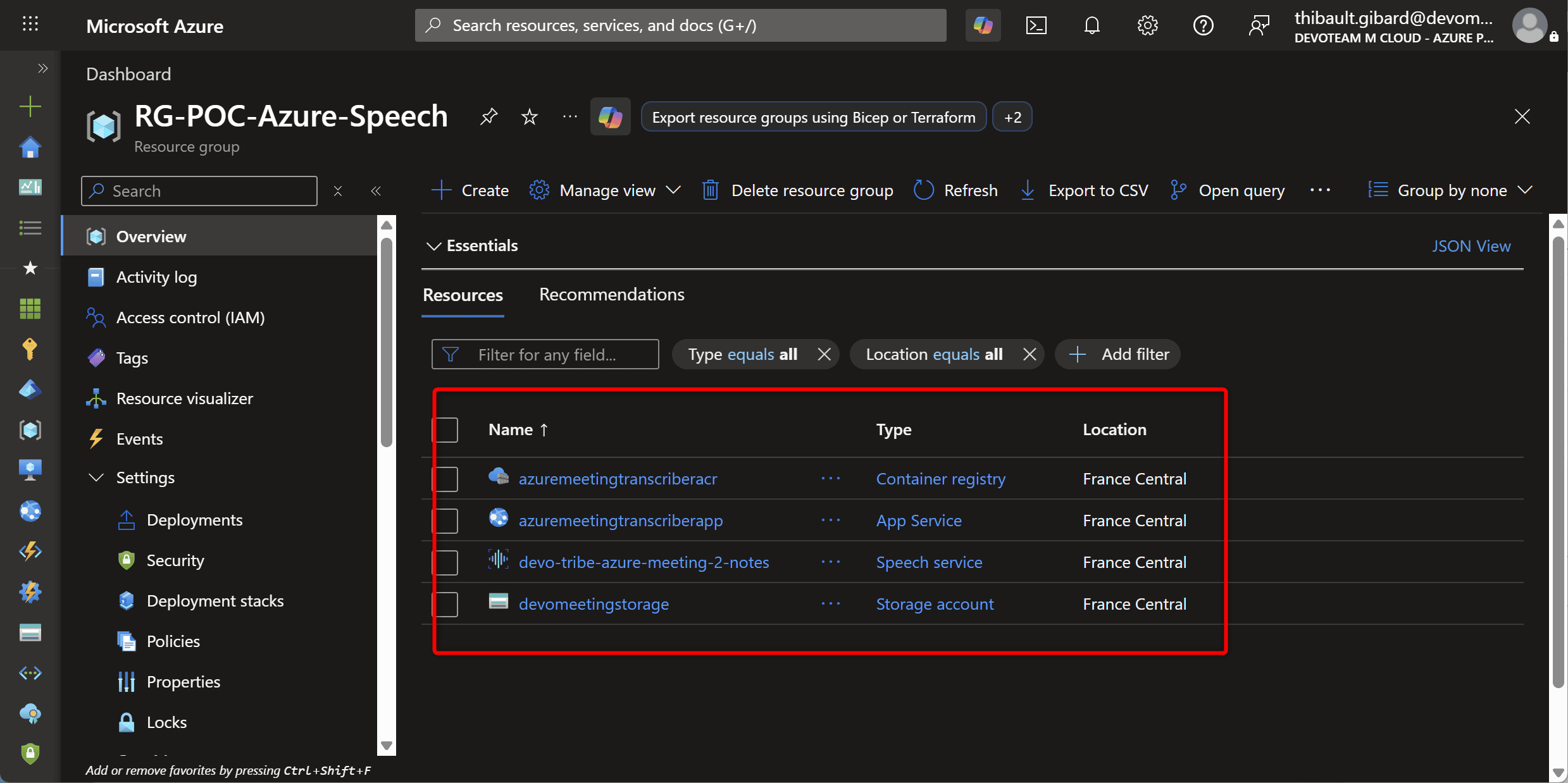
Pour faire tourner tout ça, il vous faut 4 ressources Azure dans le même Resource Group :
| Ressource | Rôle |
|---|---|
| Storage Account | Stocke temporairement l’audio uploadé |
| Speech Service | Transcrit l’audio en texte |
| Container Registry (ACR) | Héberge l’image Docker de l’app |
| Web App | Fait tourner l’app |
⚠️ Attention à la région : prenez francecentral ou westeurope pour le Speech Service — c’est là que la transcription française est la plus performante. Et restez cohérent : toutes les ressources dans la même région, sinon vous payez du transit réseau pour rien.
Côté Speech Service, créez-le avec le tier Standard S0 (pas le tier gratuit F0 qui ne supporte pas la Batch API). Une fois créé, récupérez la clé et la région dans la rubrique « Keys and Endpoint » — on va en avoir besoin tout de suite.
La brique centrale : Azure Speech Batch API
C’est le morceau le plus intéressant du projet, et celui que j’ai eu le plus envie de partager parce qu’il est étonnamment peu documenté en français.
Azure Speech propose deux modes de transcription :
- Mode streaming temps réel : tu pousses de l’audio en continu, tu récupères le texte au fil de l’eau. Idéal pour de la dictée vocale ou un sous-titrage live.
- Mode batch : tu pointes un fichier audio (URL accessible), Azure le traite en arrière-plan, et tu viens chercher le résultat quand c’est prêt.
Pour notre cas d’usage — un enregistrement de réunion de 30 minutes ou plus — le mode batch est le seul viable :
- Pas besoin de garder une connexion ouverte
- Géré pour les fichiers longs (jusqu’à plusieurs heures)
- Moins cher au coût/minute que le streaming
- Supporte plusieurs locuteurs et la ponctuation automatique
Le workflow batch tient en 3 appels HTTP successifs :
1. POST /speechtotext/v3.2/transcriptions → on crée un job
2. GET /transcriptions/{id} → on poll le statut
3. GET {files-url} → on récupère le texte une fois "Succeeded"
C’est ce qu’on va dérouler dans les étapes suivantes.
Étape 1 : uploader l’audio sur Azure Blob Storage
Première subtilité : Azure Speech Batch ne sait pas lire directement un fichier qu’on lui pousse. Il faut lui fournir une URL HTTPS publique (ou signée) vers l’audio. La solution standard, c’est de stocker l’audio sur Azure Blob Storage, puis de générer une URL SAS (Shared Access Signature) qui donne un accès temporaire au blob.
D’abord, créez un container dans votre Storage Account (ex: audio-uploads) :
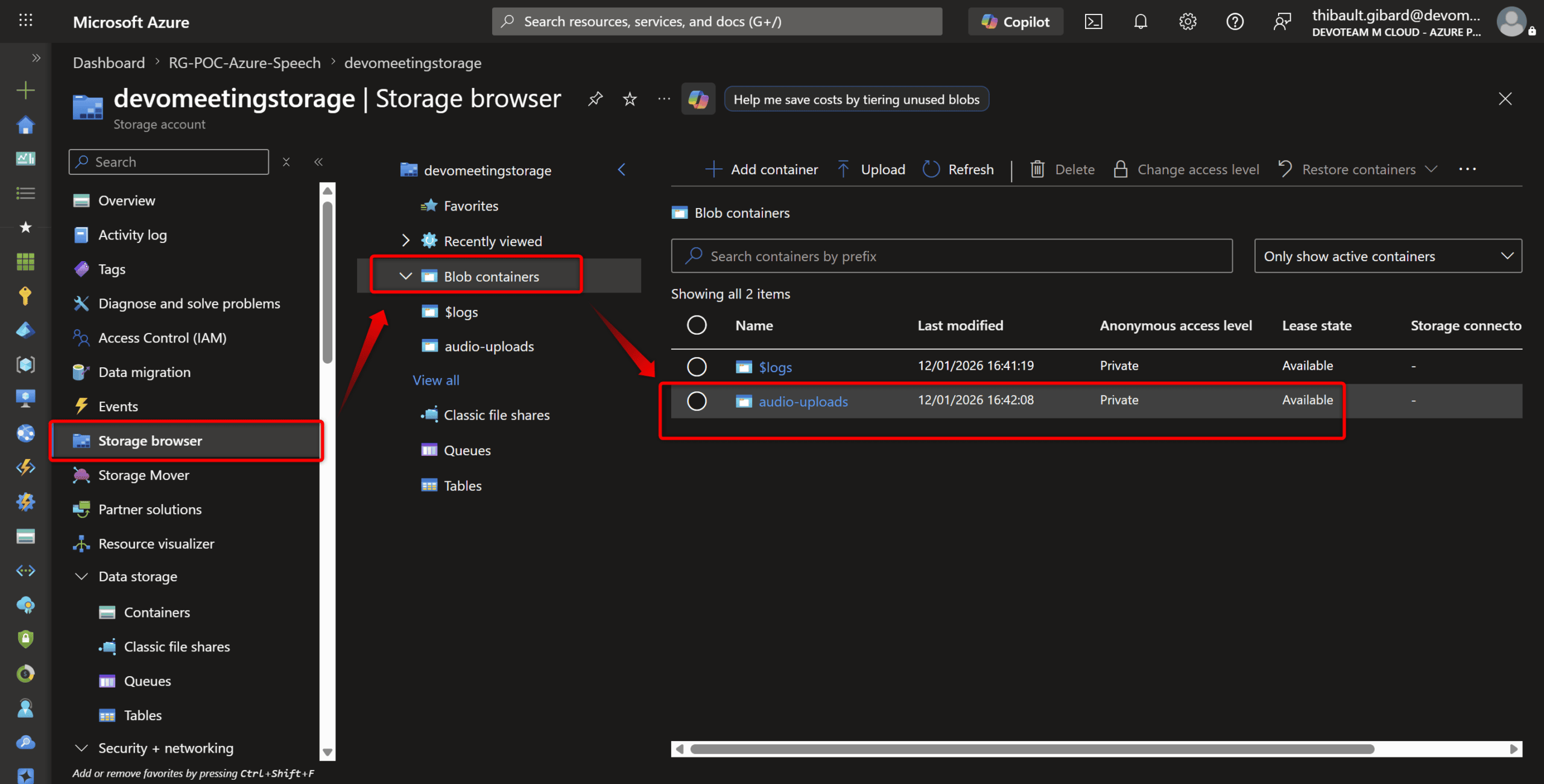
Côté code, on uploade le fichier en HTTP PUT classique. Voici la version simplifiée :
const https = require('https');
async function uploadToAzure(blobName, data, contentType) {
const url = generateSasUrl(blobName); // URL signée (voir plus bas)
const urlObj = new URL(url);
return new Promise((resolve, reject) => {
const req = https.request({
hostname: urlObj.hostname,
path: urlObj.pathname + urlObj.search,
method: 'PUT',
headers: {
'Content-Type': contentType,
'Content-Length': data.length,
'x-ms-blob-type': 'BlockBlob'
}
}, (res) => {
if (res.statusCode === 201) resolve(url);
else reject(new Error(`Upload failed: ${res.statusCode}`));
});
req.on('error', reject);
req.write(data);
req.end();
});
}
L’URL SAS générée aura la forme suivante :
https://<account>.blob.core.windows.net/<container>/<blob>?sv=...&se=...&sig=...
⚠️ L’URL SAS est sensible : elle donne un accès temporaire au blob (1 heure dans mon implémentation). Ne la logguez pas, ne la stockez pas plus longtemps que nécessaire. Pour ce qui est de la générer, vous avez deux options :
- SDK Azure (
@azure/storage-blob) — c’est la solution propre et recommandée en production - Génération manuelle avec
crypto.createHmac('sha256', ...)— plus léger, sans dépendance, mais à manipuler avec précaution
J’ai utilisé la version manuelle dans mon projet pour rester sans dépendance npm, mais pour un projet d’équipe, prenez le SDK : c’est ce que Microsoft recommanderait et les évolutions d’API seront gérées à votre place.
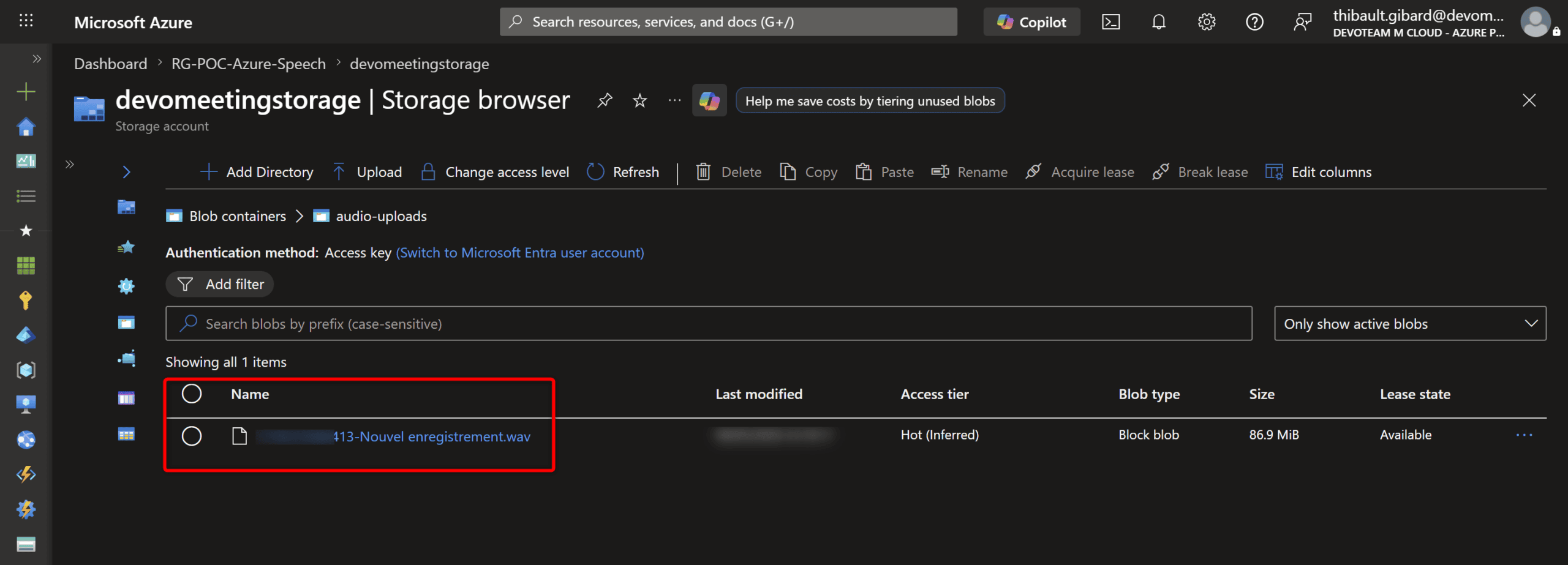
Étape 2 : créer un job de transcription
Une fois l’audio dans Blob Storage et l’URL SAS en main, on peut demander à Azure Speech de transcrire. C’est un simple POST :
async function createTranscriptionJob(audioUrl) {
const endpoint = `https://${REGION}.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions`;
const body = JSON.stringify({
contentUrls: [audioUrl], // URL SAS du blob
locale: 'fr-FR', // Langue
displayName: `transcription-${Date.now()}`,
properties: {
punctuationMode: 'DictatedAndAutomatic', // Ponctuation auto
profanityFilterMode: 'None' // Pas de filtre
}
});
return new Promise((resolve, reject) => {
const req = https.request({
hostname: `${REGION}.api.cognitive.microsoft.com`,
path: '/speechtotext/v3.2/transcriptions',
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Ocp-Apim-Subscription-Key': SPEECH_KEY,
'Content-Length': Buffer.byteLength(body)
}
}, (res) => {
let data = '';
res.on('data', chunk => data += chunk);
res.on('end', () => {
if (res.statusCode === 201) resolve(JSON.parse(data));
else reject(new Error(`Job creation failed: ${res.statusCode}`));
});
});
req.on('error', reject);
req.write(body);
req.end();
});
}
La réponse contient un champ self qui est l’URL du job — c’est cette URL que l’on va interroger en boucle dans l’étape suivante pour savoir si c’est terminé (un peu comme votre gosse en voiture qui vous demande quand est-ce qu’on arrive…) ! 🤣
💡 Astuce : Azure accepte des hints de domaine via la propriété customProperties pour améliorer la transcription d’un jargon métier (acronymes, noms de produits…). Très utile si vous transcrivez des réunions tech avec plein de noms d’outils, sinon Azure va sortir « as your » pour « Azure » 😅 !
Étape 3 : récupérer la transcription quand elle est prête
Le job tourne en arrière-plan chez Azure. On check son statut toutes les 30 secondes jusqu’à ce qu’il passe en Succeeded :
async function pollTranscription(selfUrl) {
while (true) {
const status = await fetchJobStatus(selfUrl);
if (status.status === 'Succeeded') return status;
if (status.status === 'Failed') throw new Error('Transcription failed');
// Attendre 30 secondes avant le prochain check
await new Promise(r => setTimeout(r, 30000));
}
}
Le texte transcrit brut se trouve dans le JSON de résultat hébergé chez Microsoft. Quand le job passe en Succeeded, Azure expose un champ links.files qui pointe vers une URL d’API du genre :
https://francecentral.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/{job-id}/files
Un GET sur cette URL renvoie un JSON listant un ou plusieurs fichiers de résultat, hébergés sur le storage interne d’Azure Speech (que nous ne gérons pas et sur lequel nous n’avons pas de contrôle). Chaque entrée a une contentUrl qui pointe vers un fichier .json. C’est ce fichier .json final contient la transcription.
La structure ressemble à ça :
{
"source": "https://...mon-blob...",
"timestamp": "2026-05-08T10:30:00Z",
"durationMilliseconds": 1800000,
"combinedRecognizedPhrases": [
{
"lexical": "alors aujourd'hui on va parler de...",
"display": "Alors aujourd'hui, on va parler de...",
"itn": "...",
"maskedITN": "..."
}
],
"recognizedPhrases": [ /* phrase par phrase avec timestamps */ ]
}
C’est le champ combinedRecognizedPhrases[0].display que nous récupérons et que nous allons transmettre à notre IA (Claude dans notre cas d’aujourd’hui). C’est la version « lisible » avec ponctuation et majuscules. Le lexical est la version brute en minuscules sans ponctuation.
⚠️ Point important sur la durée de vie : Azure conserve ces fichiers de résultat par défaut pendant un temps limité (de mémoire 12h à quelques jours selon le tier). Donc si vous souhaitez les garder / archiver même après le traitement alors vous devez le stocker dans un storage account. Dans notre cas du jour, je transmet juste à Claude pour qu’il mette toute la transcription en forme (déjà parce que j’ai pas besoin de le garder et d’un point de vue RGPD c’est également intéressant de ne pas l’archiver).
Une fois le job en Succeeded, l’API renvoie un champ links.files qui pointe vers la liste des fichiers de résultat. Un GET sur cette URL renvoie un JSON listant le ou les .json de transcription. Encore un GET sur le bon, et on a notre texte transcrit.
Étape 4 : générer le compte-rendu avec Claude
À ce stade on a un gros pavé de texte brut. C’est utile, mais un humain n’a pas envie de lire 8000 mots de transcription — il veut le résumé, les décisions, les actions à mener. C’est là que le LLM entre en jeu.
J’ai choisi Claude (Anthropic) parce que je le trouve excellent pour la synthèse en français, mais vous pouvez tout à fait utiliser GPT-4 ou Gemini à la place — l’idée est la même. Il vous suffit de créer une nouvelle clé d’API sur l’interface du LLM que vous aurez choisi. Pour Claude, voici l’URL en un seul clic : https://platform.claude.com/settings/workspaces/default/keys.
async function callClaude(transcription, promptType, context) {
const systemPrompt = PROMPTS[promptType] || PROMPTS['confcall'];
const userMessage = (context ? `**Contexte :** ${context}\n\n` : '')
+ `---\n\n${transcription}`;
const body = JSON.stringify({
model: 'claude-sonnet-4-20250514',
max_tokens: 4096,
system: systemPrompt,
messages: [{ role: 'user', content: userMessage }]
});
// ... requête HTTPS classique vers api.anthropic.com/v1/messages
// ... avec le header 'x-api-key' et 'anthropic-version: 2023-06-01'
}
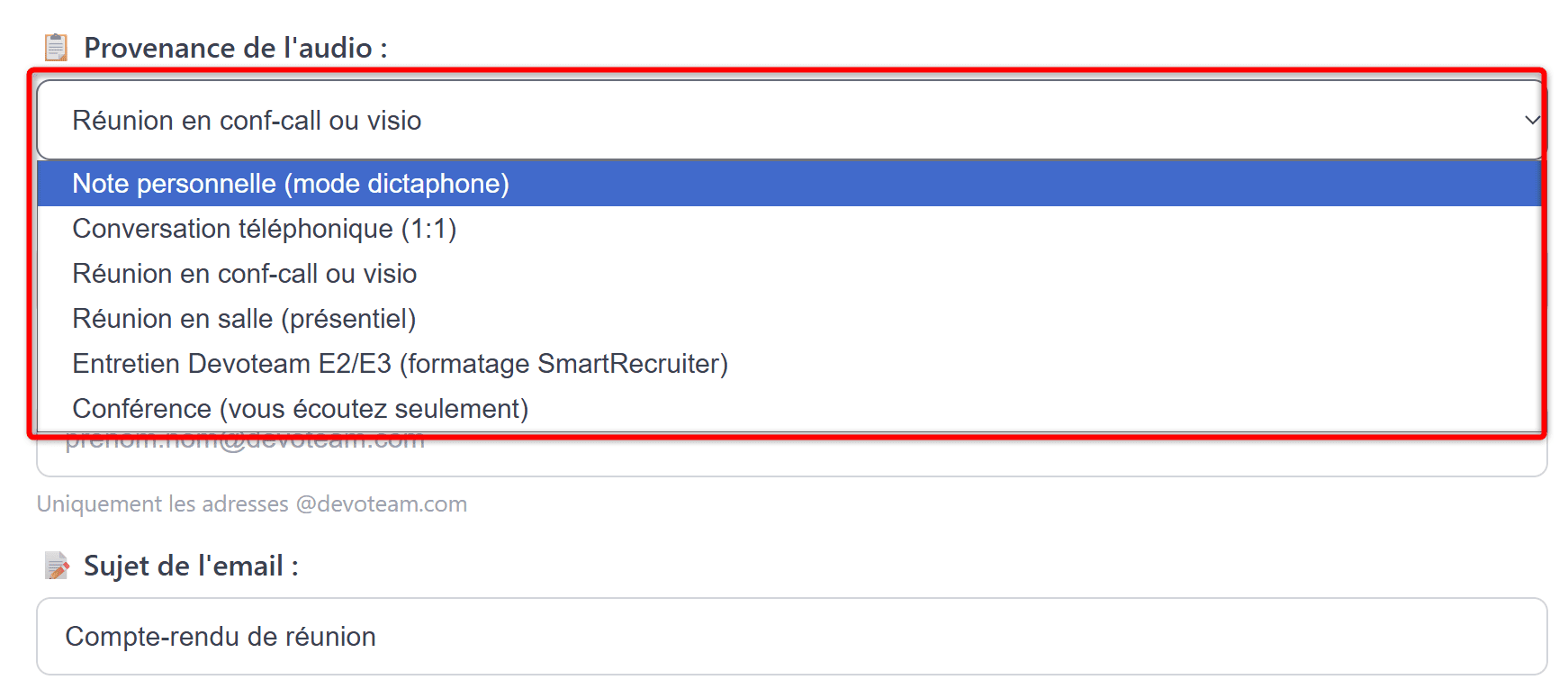
Rapidement le problème auquel j’ai dû faire face c’est que Claude avait besoin d’informations : même d’une phrase, pour savoir de quel type d’enregistrement il s’agissait :
- est-ce une confcall avec de multiples participants ?
- un échange téléphonique ? (uniquement 2 personnes)
- un entretien de recrutement ? (présence de questions/tests)
- une conférence ? (celui qui enregistre ne parle à priori pas)
La vraie subtilité : un prompt par type de réunion
C’est l’astuce qui change tout par rapport à un résumé générique. Toutes les réunions ne se résument pas pareil : un entretien de recrutement n’a pas la même structure qu’une conf-call client ou qu’une note vocale dictée pendant un trajet en voiture.
J’ai donc 6 prompts différents dans un fichier prompts.js, et l’utilisateur choisit le type au moment de l’upload :
const PROMPTS = {
'note': `Tu es un assistant qui analyse des notes vocales personnelles...`,
'phone': `Tu rédiges un compte-rendu de conversation téléphonique 1:1...`,
'confcall': `Tu es spécialisé dans les CR de réunions visio en cabinet conseil cloud...`,
'meeting': `Tu rédiges un CR de réunion en présentiel...`,
'conference': `Tu prends des notes pour quelqu'un assistant à une conférence...`,
'interview': `Tu structures un compte-rendu d'entretien de recrutement...`,
};
Chaque prompt définit la structure attendue du CR : titres, sections, format des actions, etc. Résultat : un CR adapté au contexte, pas un résumé générique.
💡 C’est la brique la plus réutilisable du projet : ce pattern « un system prompt par type d’usage » marche pour plein d’autres cas. Articles de blog, mails commerciaux, documentation technique… Externalisez vos prompts dans un fichier dédié et vous pouvez les itérer sans toucher au code.
Vous pouvez retrouver l’exemple de mon fichier prompt.js en en suivant ce lien sur GitHub.
Étape 5 : envoyer le résultat par email
Le CR est généré, il ne reste qu’à le mettre dans un email un peu joli et l’envoyer. J’ai utilisé Brevo (ex-Sendinblue) parce que c’est un service français, le free tier est généreux (300 emails/jour), et l’API est ultra simple :
async function sendEmail(to, subject, htmlContent) {
const body = JSON.stringify({
sender: { name: 'Meeting Transcriber', email: 'noreply@example.com' },
to: [{ email: to }],
subject: subject,
htmlContent: htmlContent
});
// POST https://api.brevo.com/v3/smtp/email
// header: 'api-key: <votre_clé_brevo>'
}
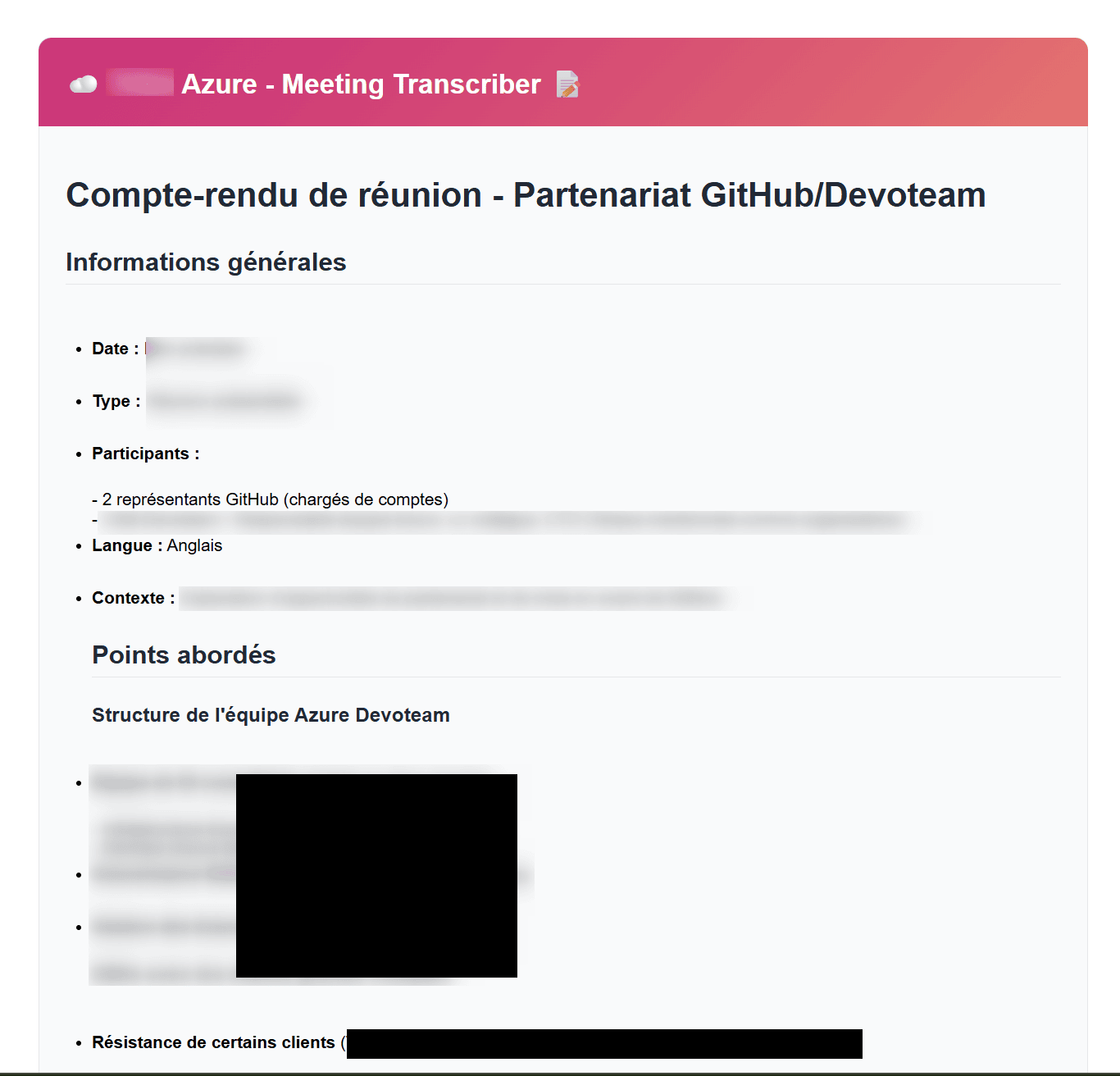
Côté template HTML, je convertis le Markdown généré par Claude en HTML stylisé avec un helper généré par Claude (rien de sorcier — gras, titres, listes, c’est tout ce qui sort du LLM). Et comme je suis toujours nul en design, c’est également lui qui me propose un formatage HTML personnalisé afin que l’email soit agréable une fois reçu.
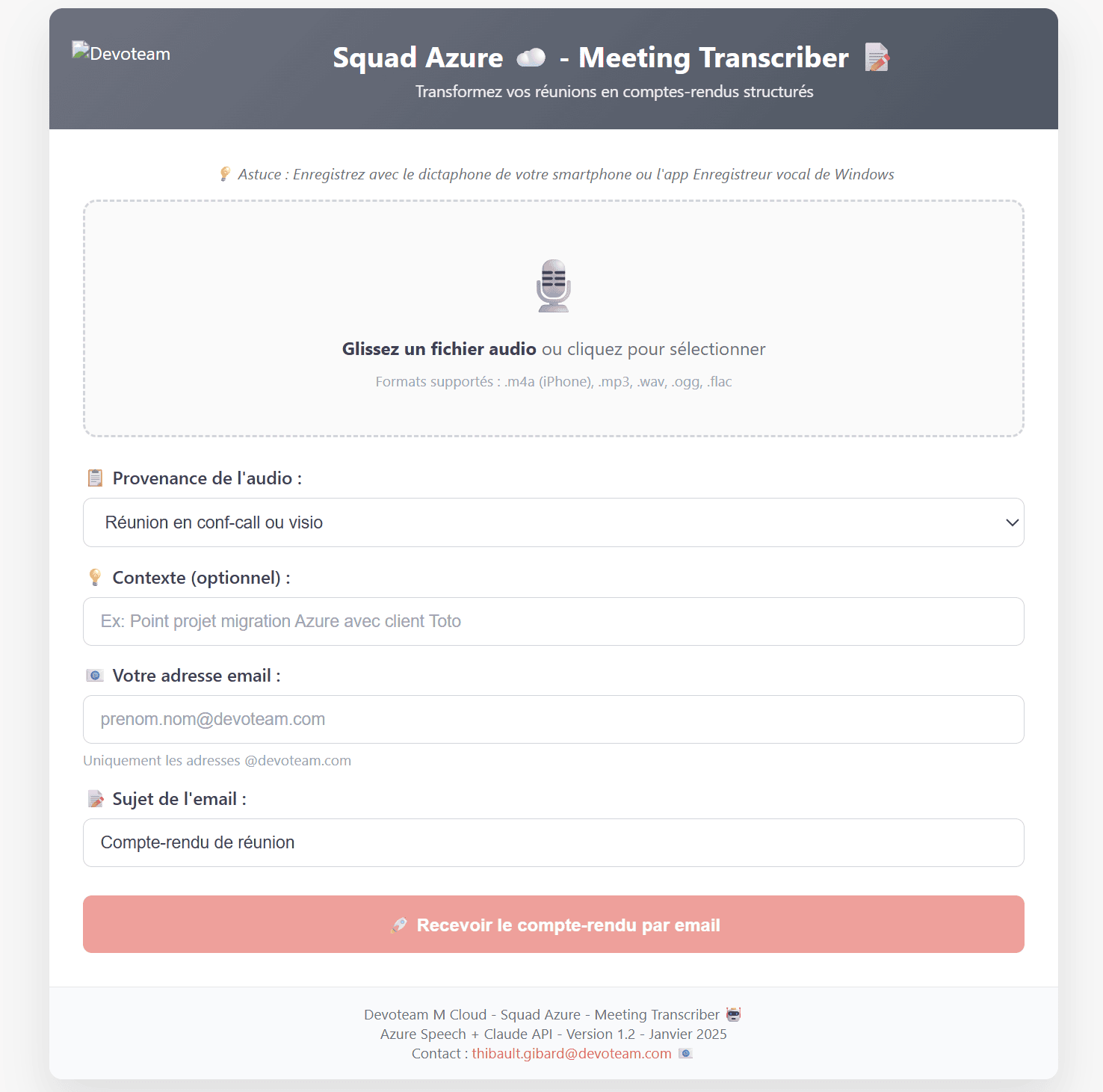
Et voici ce que vous pouvez recevoir :
Le pattern async fire-and-forget
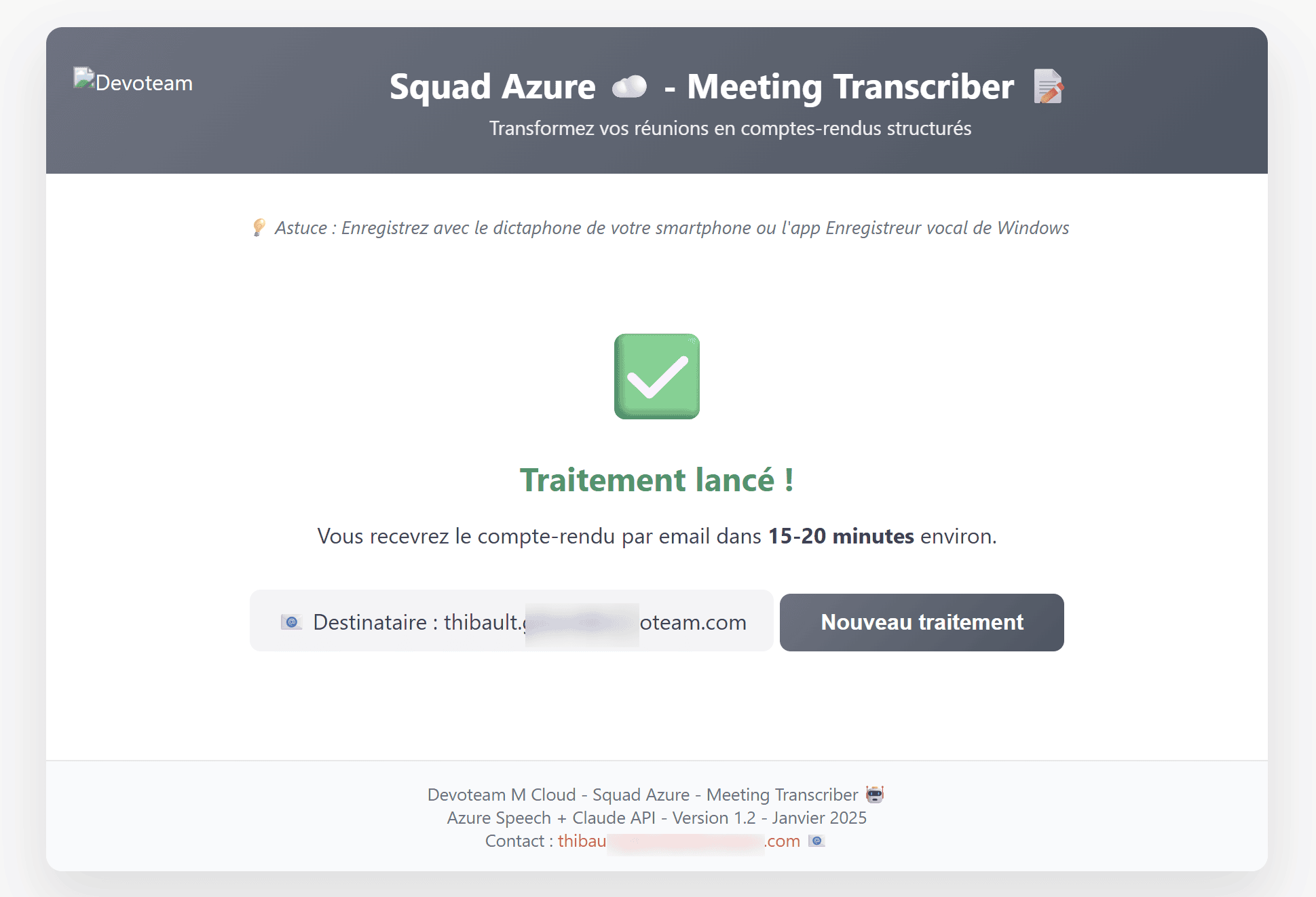
Voilà le morceau d’architecture qui rend l’expérience utilisateur fluide. Le traitement complet prend 10 à 20 minutes (dont la majorité est l’attente de la transcription Azure). Garder le navigateur ouvert pendant 20 minutes ? pas acceptable. 🤓
Donc l’idée c’est qu’en Node.js : on ne await pas la fonction de traitement, et on répond immédiatement au client (merci Claude).
if (req.method === 'POST' && req.url === '/api/process') {
// Parser l'upload multipart...
const parts = parseMultipart(buffer, boundary);
// 🔥 Lancer le traitement SANS await — il continue en arrière-plan
processAudio(parts.audio.data, parts.audio.filename, parts.type, ...);
// 🚀 Répondre immédiatement au client
res.writeHead(200, { 'Content-Type': 'application/json' });
res.end(JSON.stringify({ success: true, message: 'Traitement lancé' }));
}
Le client reçoit instantanément un « ✅ Votre demande est en cours, vous recevrez le résultat par email ». Le serveur, lui, continue à travailler de son côté.
⚠️ Caveat : ce pattern marche très bien pour un POC ou un usage interne, mais en prod sérieuse il a des limites. Si l’instance Web App redémarre pendant le traitement (déploiement, scaling…), le job est perdu. La version robuste utiliserait une file de messages (Azure Service Bus, Storage Queue) et un worker dédié. Pour l’usage qu’on en a — quelques transcriptions par semaine au sein de l’équipe — c’est largement suffisant.
Déploiement sur Azure Web App
L’app tourne dans un container Docker. Le Dockerfile est minimaliste :
FROM node:20-alpine
RUN apk add --no-cache ffmpeg # FFmpeg pour convertir M4A → WAV
WORKDIR /app
COPY . ./
EXPOSE 8080
CMD ["node", "server.js"]
💡 Pourquoi FFmpeg ? Azure Speech Batch n’aime pas le format M4A (celui de l’app Dictaphone d’iPhone par exemple). On le convertit en WAV à la volée avant l’upload. C’est un des points qui m’a pris la tête et que je ne comprenais pas pourquoi ça ne fonctionnait pas… spécificité iPhone. 🥸
Le déploiement se fait en deux temps :
1. Push de l’image vers Azure Container Registry :
docker build -t meeting-transcriber .
az acr login --name votreacr
docker tag meeting-transcriber votreacr.azurecr.io/meeting-transcriber:latest
docker push votreacr.azurecr.io/meeting-transcriber:latest
2. La Web App pointe vers cette image (dans la config « Deployment Center » du portail Azure), avec les variables d’environnement renseignées dans Configuration → Environment variables :
ANTHROPIC_API_KEY = sk-ant-...
AZURE_SPEECH_KEY = ...
AZURE_SPEECH_REGION = francecentral
AZURE_STORAGE_ACCOUNT = ...
AZURE_STORAGE_KEY = ...
AZURE_STORAGE_CONTAINER = audio-uploads
BREVO_API_KEY = xkeysib-...
EMAIL_FROM = noreply@example.com
💡 Pour la sécu en prod, ces clés devraient passer par Azure Key Vault plutôt que d’être en clair dans les App Settings. C’est un autre sujet, mais à garder en tête si le projet doit devenir autre chose qu’un POC / test comme c’était mon cas.
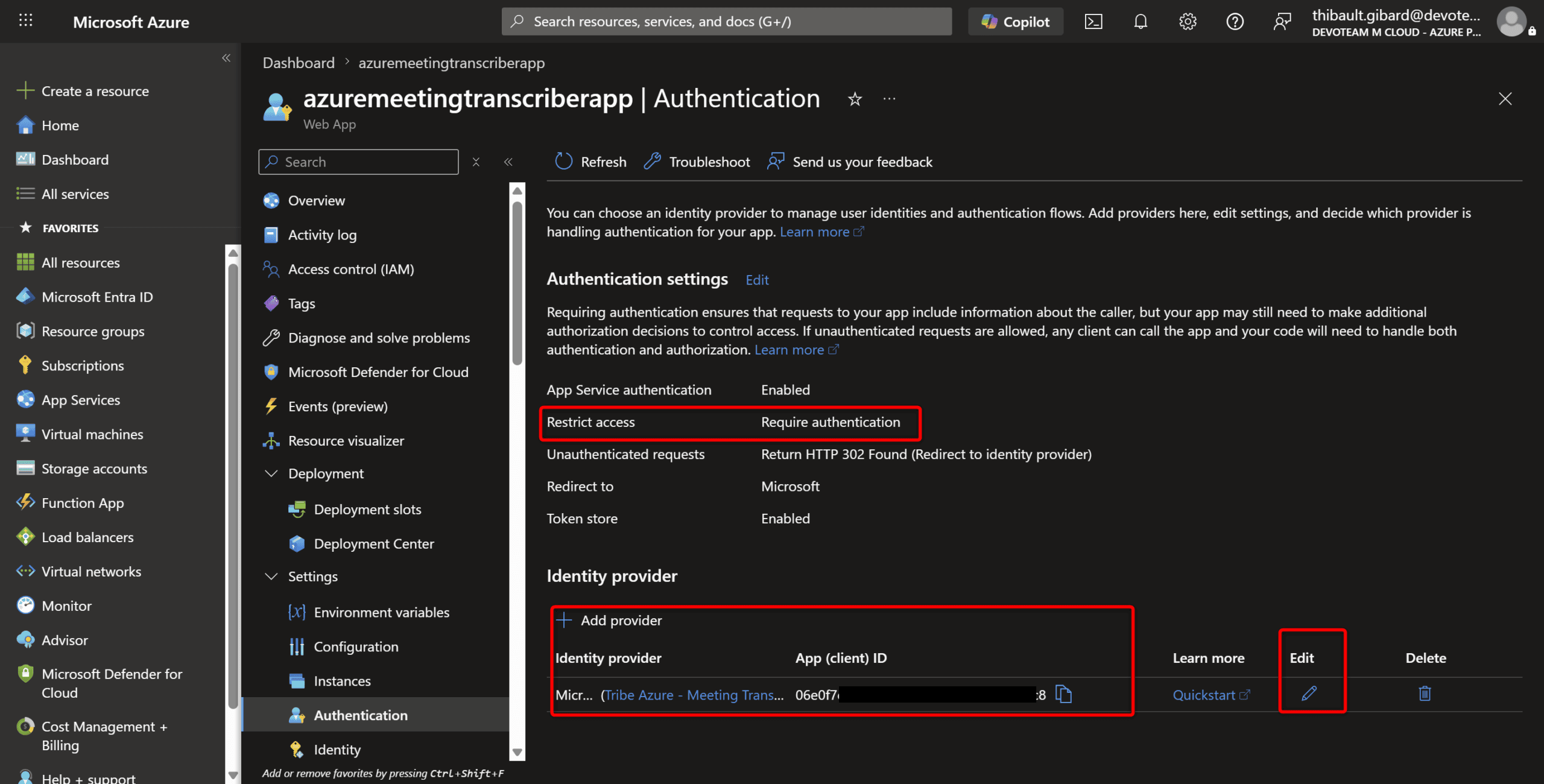
Restreindre l’accès avec Entra ID
Azure Web App propose une fonctionnalité super pratique : Easy Auth. En quelques clics dans le portail, vous activez l’authentification Entra ID (l’ex-Azure AD), et seuls les membres d’un groupe désigné peuvent accéder à l’app — sans une seule ligne de code à écrire côté serveur.
C’est exactement ce qu’il faut pour un outil interne d’équipe : pas de login/password à gérer, pas de gestion de session, et l’authentification est cohérente avec votre annuaire d’entreprise.
Avec l’App Registration qui est associée à mon application, j’ai ainsi pu créer un groupe Entra ID et restreindre l’accès à cette application à l’appartenance des comptes users membres du groupe concerné. 🙂
Bilan et coût
Coût mensuel pour un usage équipe (quelques heures d’audio par mois) :
- Azure Speech (Standard S0) : ~1 €/heure d’audio transcrit
- Azure Blob Storage : centimes (les fichiers sont supprimés rapidement)
- Azure Web App (B1 Basic) : ~13 €/mois (toujours allumé)
- Azure Container Registry (Basic) : ~5 €/mois
- Brevo : 0 € (free tier, 300 mails/jour)
- Claude API : quelques centimes par CR généré
Total : autour de 20-25 €/mois pour un outil partagé entre 10-20 personnes. À comparer avec le Plaud NotePin à 169 € + son abonnement à 7 €/mois pour les fonctionnalités IA, sachant qu’il faut un device par utilisateur.
Côté bilan technique, ce que je retiens :
- Azure Speech Batch est bluffant de qualité sur le français, dès lors qu’on a une qualité audio correcte. La ponctuation automatique est très bonne, la séparation des locuteurs aussi (option non utilisée ici mais dispo).
- Le pattern « audio → transcription → LLM » est plutôt simple à mettre en place (encore plus avec des outils comme Claude Code ou Codex), et c’est exactement ce qui fait tourner la plupart des « produits IA » qu’on voit sur le marché. Vous pouvez le décliner pour des podcasts, des cours, des appels téléphoniques, des pitchs commerciaux… 😉
- L’astuce du system prompt par cas d’usage est ce qui transforme un résumé générique en livrable utilisable. C’est aussi ce qui est le plus facile à itérer dans le temps : un prompt qui ne donne pas un bon CR de conf-call ? On modifie le
.js, on redéploie, c’est parti.
Côté comparaison avec le Plaud NotePin : honnêtement, le device a une vraie valeur dans certains contextes — réunions sans téléphone à portée, prise de note rapide en marchant, batterie autonome. Mais pour 80% des cas d’usage, l’app Dictaphone du téléphone + ce pipeline DIY fait le job. Et au passage, on garde la maîtrise complète de la chaîne — ce qui n’est pas neutre quand on transcrit des réunions sensibles.
Et puis surtout, on a appris à utiliser Azure Speech. Ce qui était l’objectif pour moi au travers de ce cas d’usage. 😉
Voir le projet sur GitHub
Pour voir le projet dans son intégralité sur GitHub, suivez ce lien.


