Dans cet article, nous allons nous intéresser à SQL Server et SSIS. Je ne vais pas présenter SQL Server mais je peux au moins décrire rapidement SSIS. Il s’agit d’un composant de SQL Server qui permet d’extraire, de charger ou de transformer les informations contenues dans vos bases de données. Dans les anciennes version de SQL Server, vous le connaissez peut-être sous le nom de DTS pour Data Transformation Services.
Le but de cet article est de présenter comment avec SSIS nous pouvons mettre à jour automatiquement en quelques clics une base de données avec avec des données contenues dans des fichiers Excel.
Pour travailler sur une situation un minimum concrète, nous allons imaginer que nous avons une liste d’utilisateurs. Ces utilisateurs disposent tous d’un ordinateur car ils travaillent sur ma prochaine super production « My Super Film » (et autant vous dire qu’ils s’agit uniquement d’acteurs de haut niveau). Je dispose bien entendu d’un outil tel que SCCM pour gérer et administrer mon volumineux parc informatique… de 10 machines. 😉
Dans cet exemple, nous utiliserons 2 sources d’informations différentes :
- Un fichier Excel, extract de l’AD, permettant d’obtenir une liste d’utilisateurs avec leurs informations essentielles : nom, prénom, adresse email, domaine de référence, compte AD, fonction ou bien encore la localisation géographique.
- Un extract de notre outil de gestion de parc pour lister l’ensemble des postes de travail, leur adresse IP, le réseau auquel ils sont connectés, la marque, le modèle ou encore la configuration RAM de la machine ainsi que le dernier utilisateur à s’être identifié sur la machine .
Vu que le but est de montrer comment nous pouvons mettre à jour une base de données à partir de données Excel, nous allons supposer que la DSI de My Super Film refuse de nous laisser accéder en direct aux sources de données (db SQL…) mais nous met à disposition chaque semaine/mois les extracts au format Excel.
Afin de conserver nos informations à jour à tout moment, nous allons donc créer une base de données avec ces 2 fichiers Excel. Nous pourrons ainsi créer une base de données rapprochant les utilisateurs de leurs postes de travail.
NB : Vous retrouverez les fichiers Excel disponibles au téléchargement à la fin de l’article.
Vous devez disposer de SQL Server, SQL Server Mangement Studio et SQL Server Data Tools (correspond à une version gratuite et orientée SQL de Visual Studio).
Etape 1 – Créer une base de données vide
Créer une base de données « vide » sur votre serveur SQL. Dans mon cas, elle portera le nom de « mysuperfilm » et nous permettra de consolider les informations du parc informatique avec les différents utilisateurs.
Etape 2 : Importer les données
Nous allons importer manuellement les 2 fichiers Excel (1 table pour chaque fichier) via SQL Management Studio.
Cliquez du bouton droit sur votre base de données et sélectionnez successivement « Tasks » puis « Import Data« .
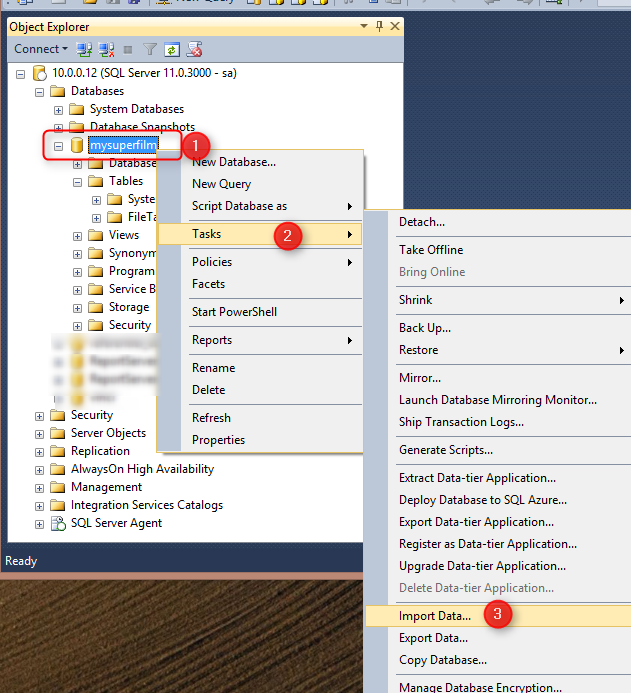
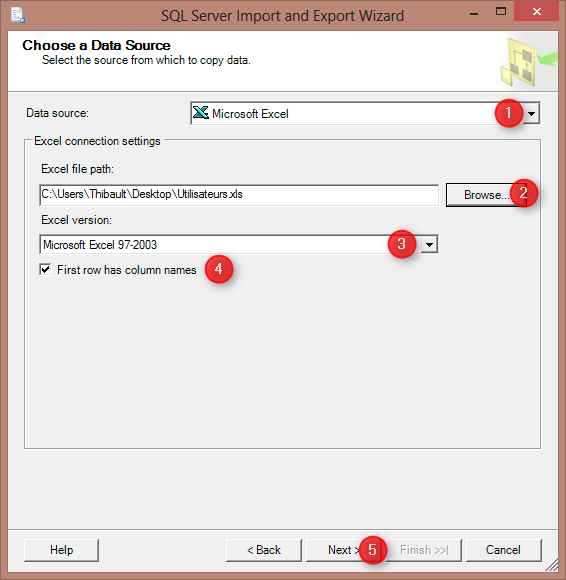
Notre source de données d’origine sera, dans un premier temps, le fichier Excel : « Utilisateurs.xls« .
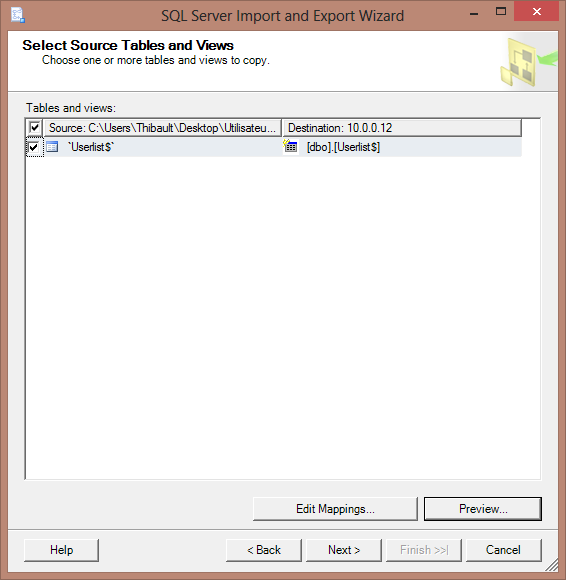
Nous sélectionnons maintenant la destination des données que nous importons. Il s’agit bien entendu de la base de données que nous avons créé à l’étape 1 et qui, dans mon cas, s’appelle « mysuperfilm ».
La façon dont vous vous identifiez au serveur SQL dépend de vous. Dans mon cas, il s’agit d’un serveur SQL standalone. J’utilise donc l’authentification SQL Server.

Cette étape dépend de votre configuration. L’adresse IP du serveur SQL cible et les identifiants pour y accéder. Dans mon cas, j’utilise de l’authentification SQL Server.
- Sélectionnez « Copy data…«
A cette étape, vous pouvez définir de nouveaux noms pour le nom des colonnes que vous allez importer dans la table SQL. Dans mon cas, je laisse les options par défaut.
- Sélectionnez « Run immediately » puis cliquez sur « Finish » (2 fois).
Si tout s’est bien déroulé, vous devriez avoir le message suivant… et de fait un nouvelle table à votre base de données.

Suivez la même succession d’étapes pour importer, votre second fichier « Gestion Parc SCCM.xls« .
Nous avons donc maintenant une base de données et 2 tables « SCCM » et « Userlist« .

Le souci ici est que nous avons réalisé cet import manuellement… Les données ne sont pas maintenues à jour automatiquement et nous n’allons pas nous amuser à vider les tables puis importer de nouveau le contenu actualisé chaque jour…
Nous allons donc utiliser SSIS afin d’importer de manière automatique nos données et ainsi actualiser l’ensemble de notre base de données. Bien évidemment, pour que ça marche, vos fichiers Excel doivent conserver le même structure d’une mise à jour à l’autre.
NB : Dans un cas réel d’utilisation, je vous recommander d’utiliser des fichiers ayant une structure la plus simple possible. Idéalement, des fichiers CSV.
Etape 3 – Création projet SSIS
Nous exécutons maintenant SQL Server Data Tools (Visual Studio 2010) et créons un nouveau projet « Integration Services« .

Nous arrivons sur une fenêtre qui doit ressembler à cela (selon la version que vous utilisez) :

Nous allons maintenant designer notre job SSIS pour qu’il importe automatiquement nos fichiers Excel au sein d’une base de données.
NB : Dans mon cas il s’agit de SQL Server 2012 et la table s’appelle « mysuperfilm ». Elle est hébergée sur une VM dont l’adresse IP est la suivante 10.0.0.12 (pour une meilleure compréhension des captures qui vont suivre).
Cliquez sur la partie droite et insérez une « Data Flow Task » sur votre espace de travail.

Double cliquez dessus pour configurer en détails votre Data Flow Task.
Nous allons maintenant définir une première source d’entrée à insérer dans notre base de données : notre premier fichier Excel, « Utilisateurs.xls« . Pour ce faire, sélectionnez dans la Toolbox le composant « Excel Source » (dans « Other Sources« ) et insérez le sur votre espace de travail par glisser-déposer.
Cliquez du bouton du bouton droit sur ce composant et sélectionnez « Edit » puis le bouton « New » dans la nouvelle fenêtre qui apparaît. Nous allons définir le fichier Excel à importer dans notre base de données.

Notre fichier dispose effectivement de noms de colonnes, nous cochons donc l’option « First row…« . Mon fichier a été créé sous Excel 2013 mais a été enregistré au format XLS pour une meilleure compatibilité.
Si tout s’est bien passé, vous retourner à la fenêtre précédente et il devrait détecter le nom de notre (unique) feuille Excel. Vous pouvez éventuellement prévisualiser les données via le bouton « Preview« .
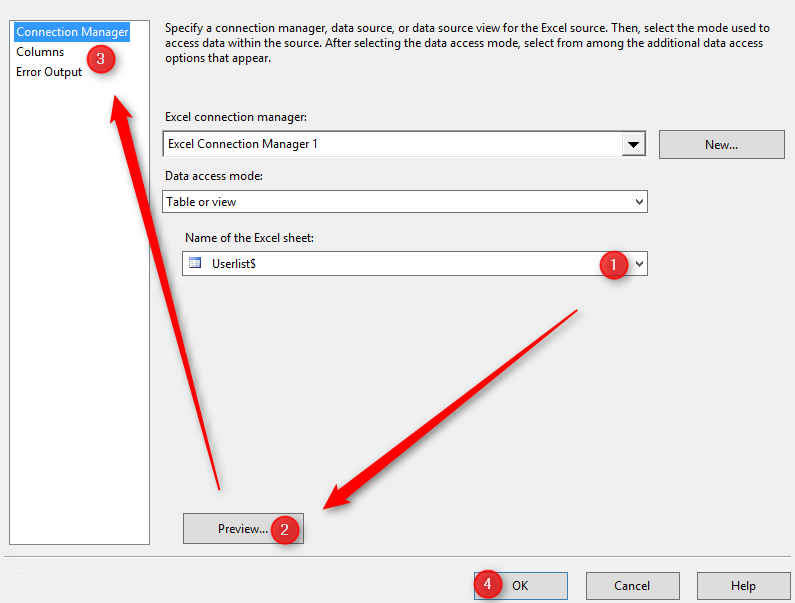
A ce niveau, vous avez toute latitude sur la façon et le type de données que vous souhaitez récupérer de ce fichier. Quelle feuille voulez-vous récupérer ? Voulez-vous renommer le nom des colonnes pour changer leurs noms une fois importées dans la table SQL ? Dans cet exemple, je laisse tout par défaut et je termine en cliquant sur « OK ».
Notre première source de données a été correctement identifiée, le symbole de « croix rouge » disparaît du composant « Excel source« .
Nous réalisons maintenant la même succession d’étape pour ajouter notre second source de données Excel, le fichier « Gestion Parc SCCM.xls ». Si tout se passe bien, vous devriez maintenant obtenir quelque-chose qui ressemble à ça :
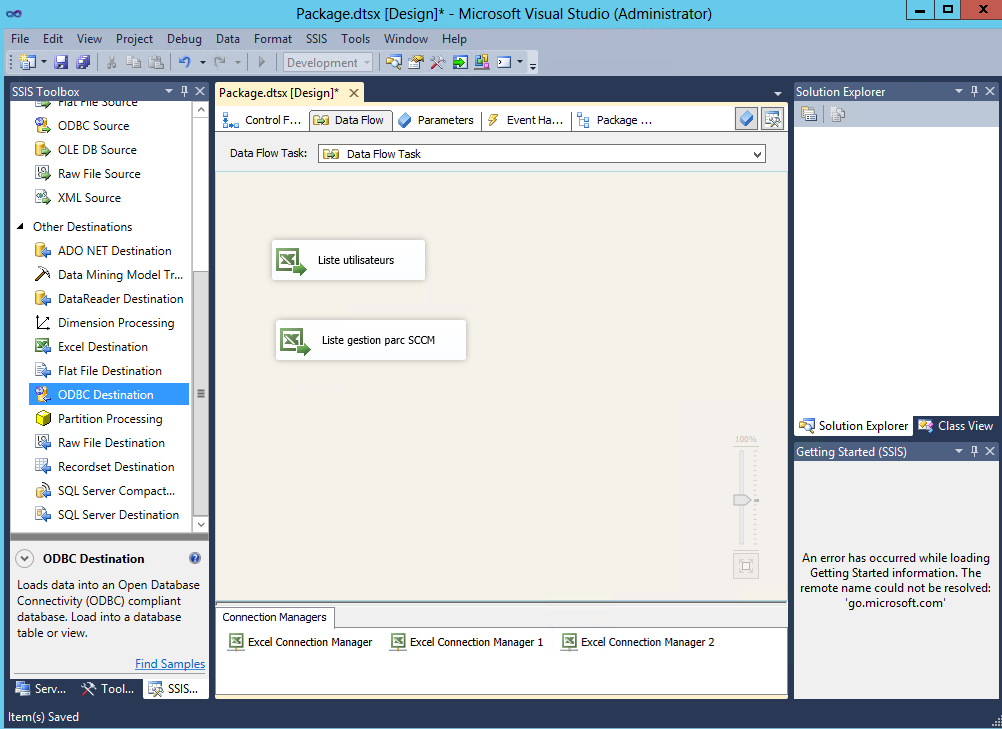
NB : Vous pouvez renommer chacun des composants pour une meilleure lisibilité.
Les sources de données à importer sont maintenant explicitées. Ils ne nous reste plus qu’à lui dire où les importer !
Pour ce faire, nous allons utiliser le composant « OLE DB Destination » dans la section « Other Destinations« . Glisser-déposer ce composant sur votre espace de travail. Nous allons maintenant connecter ensemble chacun des différents composants en présence.
Pour ce faire, cliquez sur chaque composant Excel, cliquez sur la flèche bleu et connectez le à un composant « OLE DB Destination« . Vous devez réaliser la même connexion pour chaque composant Excel, il vous faudra donc 2 composants « OLE DB Destination« .

Nous allons maintenant configurer les 2 composants « OLE DB Destination » (que j’ai renommé) en cliquant du bouton droit puis en sélectionnant l’option « Edit ». Vous allez probablement avoir le message d’erreur suivant :
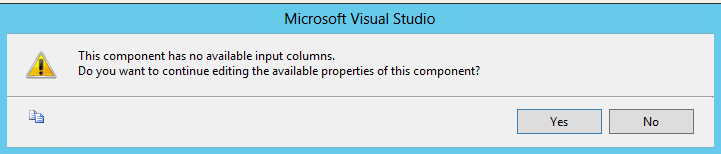
C’est normal ! 🙂
Il faut indiquer à chaque composant « OLE DB Destination » ce qu’il aura comme données en entrées. Pour ce faire, on connecte chaque composant « Excel source » à un composant « OLE DB Destination » en utilisant la flèche bleu.
C’est connecté ? Cliquez à nouveau du bouton droit sur un premier composant « OLE DB Destination » et sélectionnez « Edit » puis « New » sur la première fenêtre qui apparaît… et encore « New » sur la seconde.
Il nous faut maintenant configurer le serveur SQL auquel nous connecter.
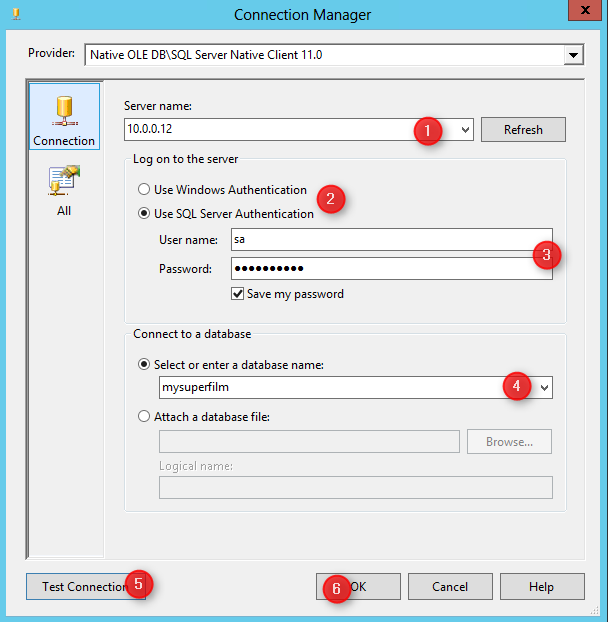
Une fois revenu à la fenêtre suivant, vous devriez pouvoir choisir parmi la liste des tables qui ont été détectées dans votre base de données.
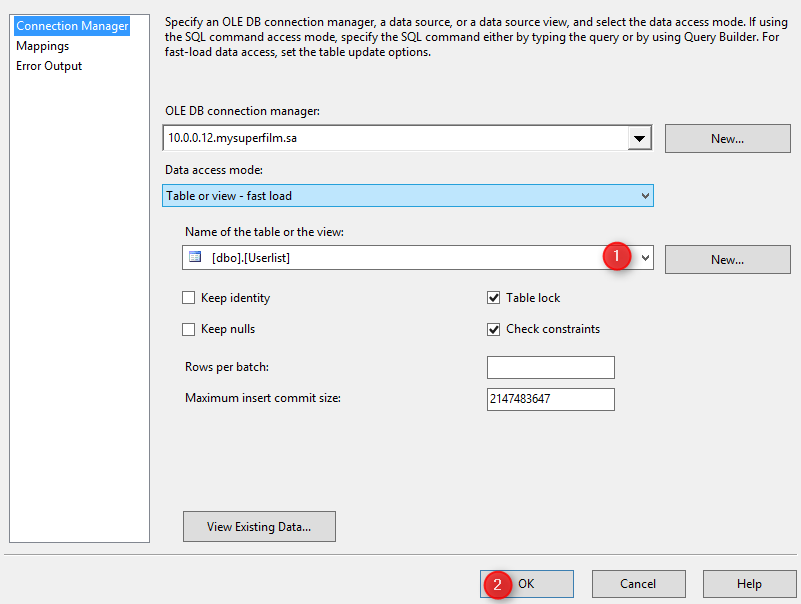
Notre première série de composants Excel Source + OLE DB Destination est désormais configurée. Cela nous permettra d’importer les données de la liste des utilisateurs.
Nous réalisons maintenant la même configuration pour le fichier gestion de parc. La configuration sera toutefois un peu plus rapide, il vous suffit de faire votre choix parmi les deux menus déroulants :
- Le serveur SQL auquel se connecter (c’est le même) ;
- La table dans laquelle nous allons déverser les données (il s’agit cette fois de la table SCCM).
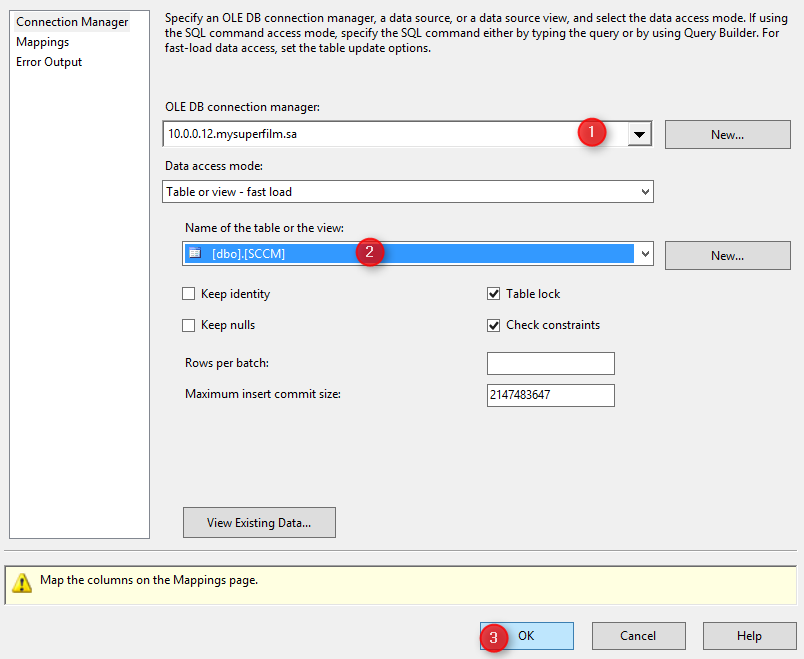
NB : Comportement étrange, vous devez afficher la section « Mappings » pour que le bouton « OK » soit accessible (le mapping étant effectué par défaut). Vous pouvez bien entendu le modifier à cette étape en fonction de vos besoins.
Si vous avez tout configuré correctement, le symbole « croix rouge » disparaît des composants « OLE DB Destination« .
Etape 4 – Exécution et import des données
Si vous avez bien suivi jusque-là, vous pouvez maintenant importer vos données en exécutant le projet SSIS. Comme tout projet Visual Studio, utilisez le bouton vert lecture pour démarrer… 🙂
Vous devriez avoir une erreur ! 🙁
Pour information, l’environnement que j’utilise se présente comme suit : Windows Server 2012 + SQL Server 2012 + Visual Studio 2012 with SQL Server Data Tools.
Si vous avez rencontré une erreur, vous pouvez visualiser les détails de cette erreur, en cliquant dans la partie supérieure sur le bouton « Progress« .

Dans mon cas, il me dit en substance, qu’il préférerait que j’exécute mon package SSIS en 32 bits…
J’ignore pourquoi il ne veut pas l’exécuter en 64 bits ou pourquoi par défaut il s’est mis sur ce mode… Quoiqu’il en soi, nous pouvons modifier ce paramètre en cliquant du bouton droit sur le nom du projet (à droite) puis en sélectionnant « Properties« . Puis, modifier l’option Run64BitRuntime et passez là à « False« .
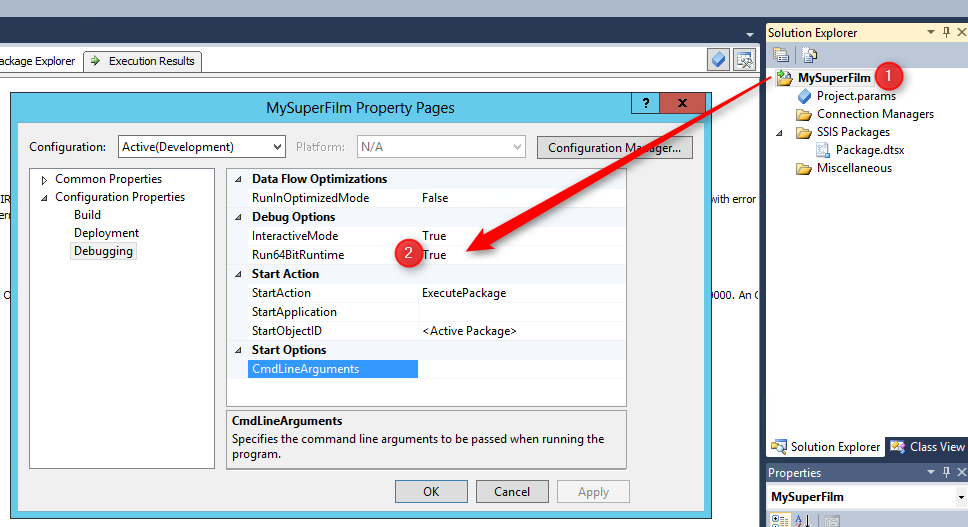
Exécutez de nouveau votre projet et ça devrait passer 🙂 !
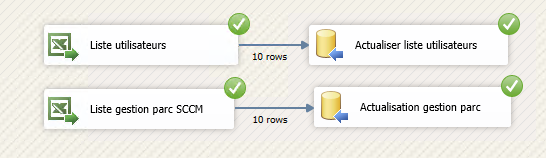
Voilà, vous avez importé vos 2 fichiers Excel par simple clic dans votre base de données.
Bien sûr dans notre exemple, c’est plutôt rapide mais imaginez que vous ayez plusieurs fichiers qui comportent chacun 30 000 ou 50 000 lignes… L’exécution sera nettement plus longue !
Nous avons toutefois oublié quelque-chose… Vous venez d’exécuter votre package SSIS… Voyons voir ce qu’il a importé dans nos tables SQL.
Etape 5 – Eviter les doublons / Purger les tables
Notre package SSIS importe les nouvelles données qui se trouvent dans nos fichiers Excel… Toutefois chaque fois que nous exécutons le projet, les données sont importées encore… et encore… Nous n’avons donc plus 10 entrées mais 20 entrées (ou plus si vous avez exécuter le projet plusieurs fois).
Pour éviter ce désagrément, il convient de vider les tables avant d’importer les nouvelles données.
Nous revenons donc sur notre Data Flow Task et nous allons ajouter un composant « Execute T-SQL Statement Task« , connecté le à votre « Data Flow Task« , puis cliquez du bouton droit « Edit« .
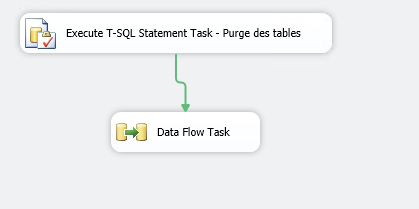
- Cliquez sur le bouton « New » et configurer sur quel serveur votre requête SQL va s’exécuter ;
- Insérer la requête SQL suivant pour purger les 2 tables avant d’importer les données.
truncate table [mysuperfilm].[dbo].[SCCM]; truncate table [mysuperfilm].[dbo].[Userlist];

Vous pouvez maintenant exécuter à nouveau votre projet SSIS :
- Les données SQL contenues dans les tables Userlist et SCCM vont d’abord être purgées ;
- Puis les nouvelles données contenues dans les fichiers Excel vont être importées à nouveau.
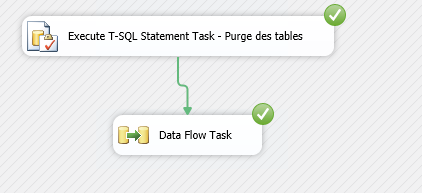
Vous pouvez vérifier à nouveau vos tables SQL et constater qu’il n’y a plus de doublons cette fois-ci.
Conclusion
De cette façon, vous pouvez facilement actualiser et/ou mettre à jour une base de données SQL avec des données provenant de fichiers Excel. Il vous suffit par exemple d’écraser les anciens fichiers par les nouveaux et exécuter de nouveau votre projet SSIS pour mettre à jour les données.
Mieux encore, vous pouvez imaginer récupérer les fichiers Excel automatiquement par scripting… Il ne resterait alors plus qu’à exécuter le package SSIS pour actualiser les données… Encore mieux d’encore mieux, vous exécuter le package SSIS via une tâche cron chaque jour au moment qui vous arrange… Vos données sont alors actualisées automatiquement.
Bref, vous l’aurez compris il y a une multitude d’améliorations possibles.
Ressources
Comme d’habitude, vous trouverez-ci-dessous les 2 fichiers Excel que j’ai utilisé dans ce test.
Dans le prochain article je m’intéresserai à PowerPivot et je repartirai de ce même exemple de base de données.



Bonjour,
l’option de vider les tables avant de réimporter est utile.
Mon problème est un peu différent :
Je veux chaque jour ajouter les lignes de la veille.
Je ne peux pas vider la table de destination car l’historique n’existe plus ailleurs, et il serait trop long de l’importer à chaque fois.
Les nouveaux fichiers ne sont pas très propres, c’est à dire qu’il reste des lignes des jours précédents.
Comment puis-je placer un filtre sur la date (l’équivalent d’une clause where) pour n’importer que les lignes dont la date est supérieure à une valeur ?
Merci
Bonjour Ivan, je n’ai pas de DB test sous le main. Mais vu la spécificité de ton besoin, pourquoi ne pas faire une requête de type T-Statement dans laquelle tu préciserai justement avec une condition where ce que tu souhaites ou non importer ?
Bonjour Thibault,
merci pour ta réponse, c’est ce que j’ai fait,
j’ai collé une requête SQL avec la clause where dans le flux.
Merci
Super ! Bonne continuation Ivan. 🙂
Salut Thibault, Je sait que je c’est un peu tard pour m’intéresser à ton sujet mais là, j’ai un gros problème d’importation de base de donnée sharepoint dans sql. Je dispose d’un fichier WSS_Content.mdf provenant de sql 2005 que j’ai attaché dans sql 2008 r2(sur un windows serveur 2012 64 bits). Lors de l’installation de sharepoint 2010 sur ce nouveau serveur, sharepoint crée un nouveau base WSS_Content dont le nom ressemble à WSS_Content_30b4554aa29c42559596d8c3a1476683.Je compte donc importer les anciens database de WSS_Content vers celui crée par sharepoint WSS_Content_30b4554aa29c42559596d8c3a1476683. Lors de l’importation , des erreurs apparaissent(0xc0202009 0x80004005 0xC020907B……). Après des recherches sur le web, j’ai cru comprendre qu’il fallait créer un projet DTSX et qu’il fallait le lancer via DTEXEC en mode 32 bits . Comme je suis débutant, je voudrais savoir si il est possible de créer ce projet en suivant ton tuto.
Merci d’avance
Bonjour et merci pour cet article qui nous éclaire dans le monde des importations!
Je suis novice dans ce domaine du coup j’aurais des milliards de questions a vous poser mais on va s’arrêter sur 2 !
1- Lorsqu’on fait cette importation (assez régulièrement) il n’y a pas d’outil pour la création des clés primaires, des checks etc…Quel est la procédure a suivre alors? Construire une copie de la structure de cette table avec les contraintes et y copier le contenu de la 1ere table ou utiliser alter table?
2- Ça se rapproche de la question du précédent utilisateur sauf que je voudrais savoir si il est possible de remplacer uniquement certaines lignes qui sont déjà présentes dans la table suivant la valeur de plusieurs variables? Par exemple remplacer automatiquement les lignes du pays P des années A (présentes dans le nouvel import) sachant que les mises a jour ne portent pas sur le même pays et/ou les mêmes années a chaque fois (j’en demande sans doute trop la?).
En tout cas merci beaucoup si vous prenez le temps de me répondre!
Bonjour Mumu
C’est délicat de te répondre de manière précise avec des captures d’écran puisque depuis 1 an… je n’ai plus la VM à ma disposition sur lequel j’avais mis en place ce système.
Pour la première question, que tu disposes d’une base de données avec ou sans clés primaires, il est possible de définir lors de l’import de tes données, par exemple un fichier Excel comme ici, quelle est la colonne qui doit jouer le rôle de clé primaire.
Pour le seconde question, je ne suis pas sûr de comprendre ton cas d’utilisation mais si tu souhaites modifier le contenu de ta base de données suivants des contraintes spécifiques, c’est réalisable en important dans VS un objet « Execute T-SQL Statement » puis en indiquant les requêtes SQL brutes. De la même façon que je réalisais un truncate tu peux exécuter tout type de requête pour ALTER telle ou telle partie de ta base de données.
Bonjour
merci beaucoup pour cet article , j’ai un projet tutoré sur l’intégration des données ,j’aurais des questions a propos de sujet si vous pouvez m’aider !!
1-comment travailler Sql Server management studio et crier un nouveau paquet et affiche la palette de travail ??
2- comment faire pour changer la date partir d’un fichier plat qui contient le jour, le mois et l’année « How to change a Date Column into two separate columns, MONTH and YEAR?? »
3-j’ai un fichier excel qui contient 3 éditeurs pour le convertir a ce que j’ai utilise 3 conversions ou bien un seul ?