
Pourquoi un bot interne ?
Au sein de notre Squad Azure chez Devoteam M Cloud, on a tous notre chat d’équipe Google Chat – c’est là qu’on échange au quotidien, qu’on partage les infos, et accessoirement qu’on perd un peu de temps avec des memes 😉.
- Pourquoi un bot interne ?
- Architecture générale
- Côté Google Chat : créer l’application
- Le squelette du serveur (Flask)
- Première commande : /blague (statique)
- Une commande qui appelle une API externe : /chuck-norris
- Une commande qui combine une API et Gemini : /horoscope
- Le mode conversationnel : mentionner le bot avec Gemini
- Récupérer une clé API Gemini
- Brancher Gemini en Python
- Donner une personnalité au bot : le system prompt
- Lui apprendre les infos internes : la base de connaissances
- Déploiement sur Cloud Run
- Bilan et coût
L’idée, c’était de créer un bot maison qui apporte un peu de fun (blagues, horoscope, pile-ou-face) mais aussi de l’utile : statut Azure en temps réel, accès rapide aux listes de distribution internes, et surtout — on y vient — un assistant qui répond aux questions de l’équipe en s’appuyant sur notre Intranet. 🤖
Bref, mi-Discord-bot, mi-assistant interne. Le tout à un coût quasi-nul.
Si on connaît bien des solutions comme Slack avec ses bots ou Microsoft Teams, Google Chat est souvent oublié alors qu’il propose une intégration vraiment simple quand on est déjà dans l’écosystème Google Workspace. Et avec Gemini côté IA et Cloud Run côté hébergement, on reste 100% chez le même fournisseur — pratique pour la facturation et les permissions.
L’objectif de cet article n’est pas de faire un copier-coller du projet, mais de partager les briques réutilisables : comment exposer un endpoint qui parle à Google Chat, comment brancher Gemini, et comment lui faire avaler de la connaissance interne pour qu’il réponde avec un peu plus que des banalités.
Architecture générale
Avant de plonger dans le code, voici le schéma mental à avoir en tête. C’est volontairement très simple :
Utilisateur dans Google Chat
│
│ (slash command ou @mention)
▼
Google Chat API
│
│ POST JSON → HTTPS
▼
Cloud Run (Python/Flask)
│
├──→ APIs externes (JokeAPI, Chuck Norris API, RSS Azure...)
└──→ Gemini API (réponses IA)
Google Chat envoie un POST HTTPS vers notre service à chaque interaction (commande, mention, ajout du bot). On répond en JSON avec le message à afficher. Pas de WebSocket, pas de polling — c’est du request/response classique, ce qui rend Cloud Run parfait : on ne paie que quand le bot est sollicité.
Côté Google Chat : créer l’application
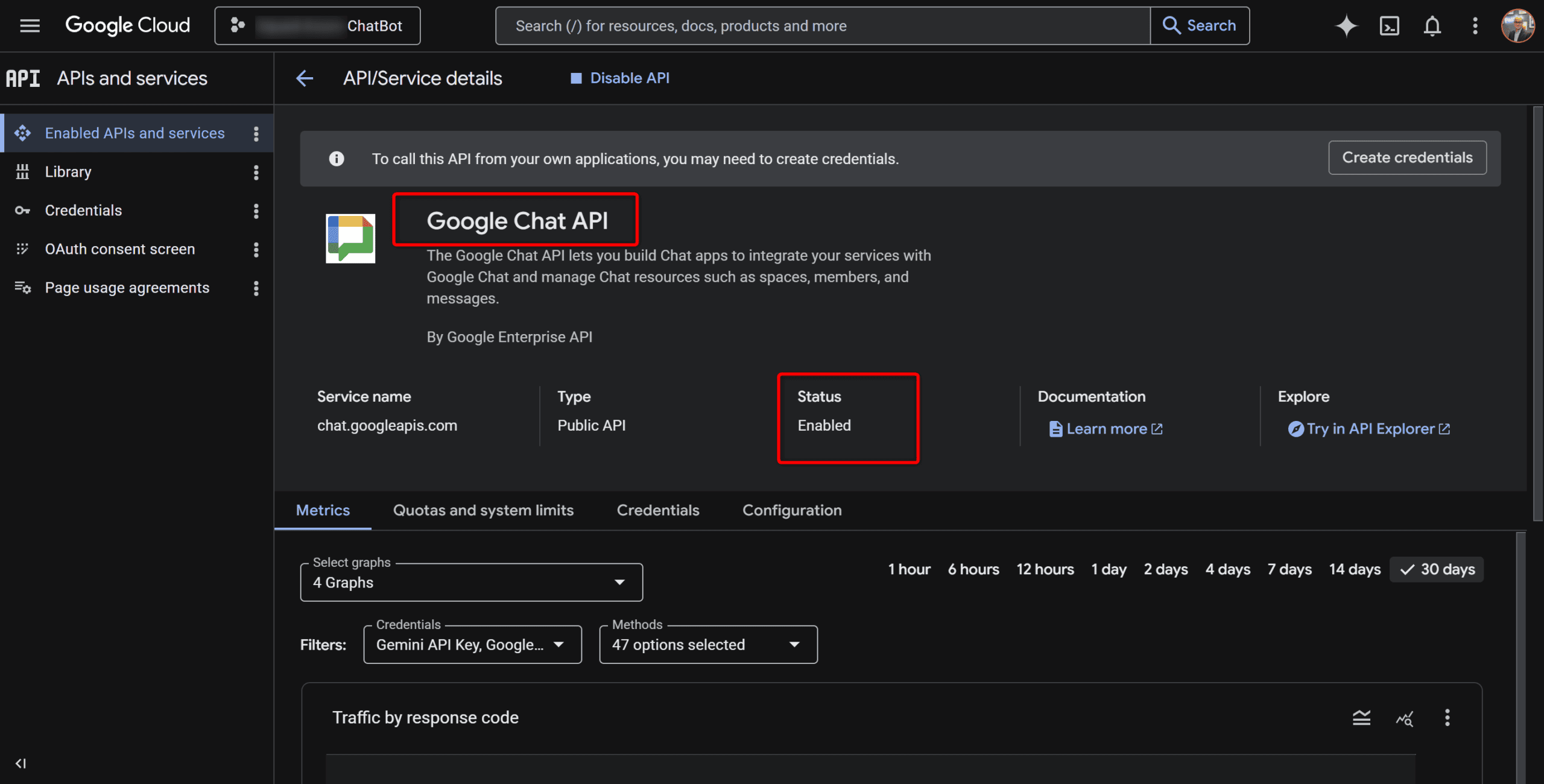
La première étape se passe entièrement dans la Google Cloud Console. Créez (ou choisissez) un projet GCP, puis activez l’API Google Chat. C’est l’API qui permet à votre code de recevoir des événements depuis Google Chat et d’y répondre.
Une fois activée, vous trouverez dans la console un onglet Configuration dédié au bot. C’est là qu’on définit :
- Le nom du bot et son avatar (mettez une URL publique vers une image — chez moi, c’est Wall-E 🤖). J’avais bien pensé à SkyNet mais il y avait une une connotation négative de fin du monde. Wall-E c’est plus « mignon ». 🤣
- L’URL du endpoint HTTPS qui recevra les événements (on y reviendra après avoir déployé sur Cloud Run)
- La portée : DM uniquement, espaces uniquement, ou les deux
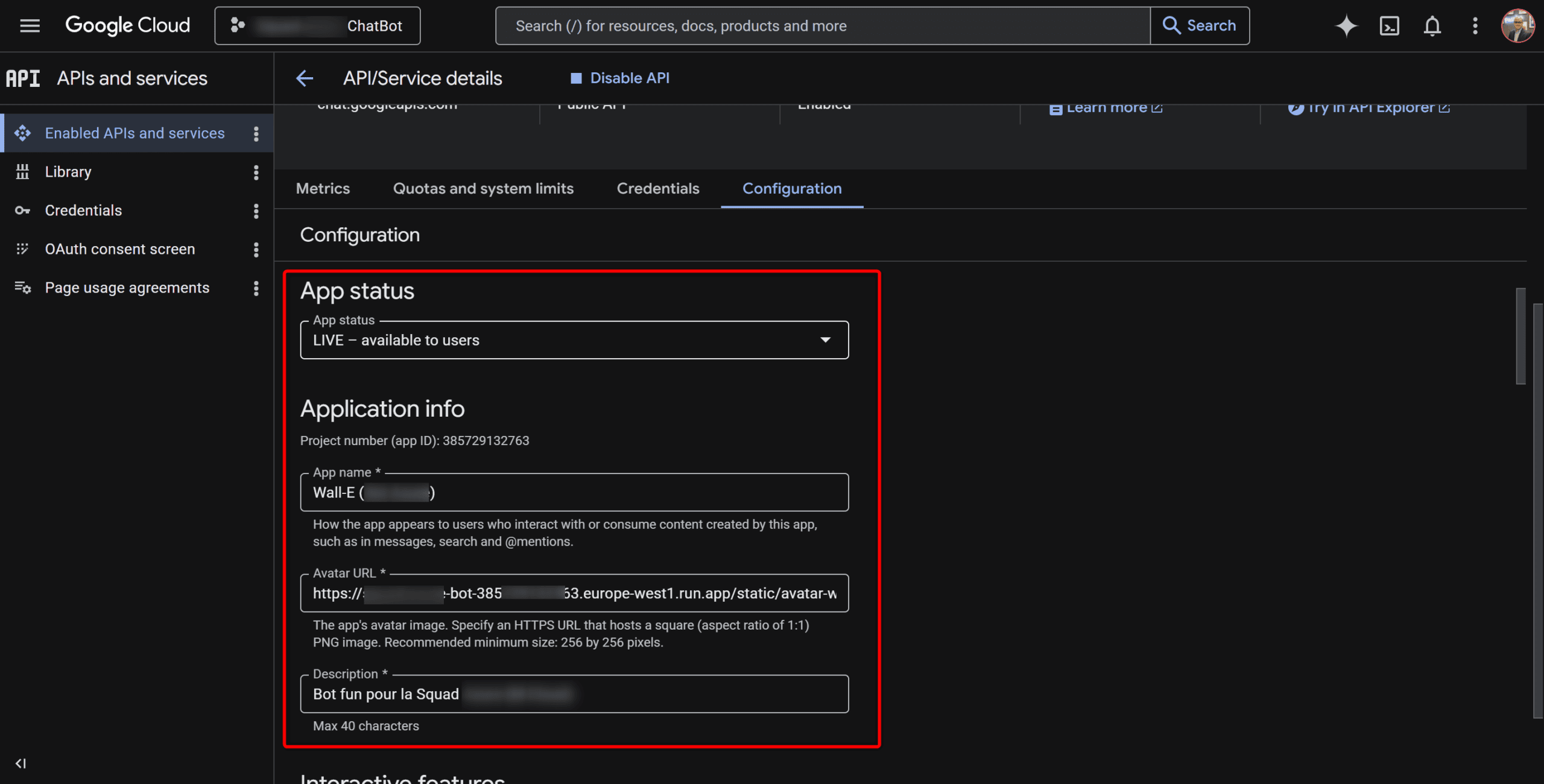
Et c’est là aussi qu’on déclare les slash commands. Chaque commande a :
- Un nom (ex:
/blague) - Un ID numérique entre 1 et 1000 (que vous choisissez vous-même)
- Une description (affichée dans le menu auto-complete de Google Chat)
- Un flag prend des arguments (oui/non — utile pour
/horoscope belierpar exemple)
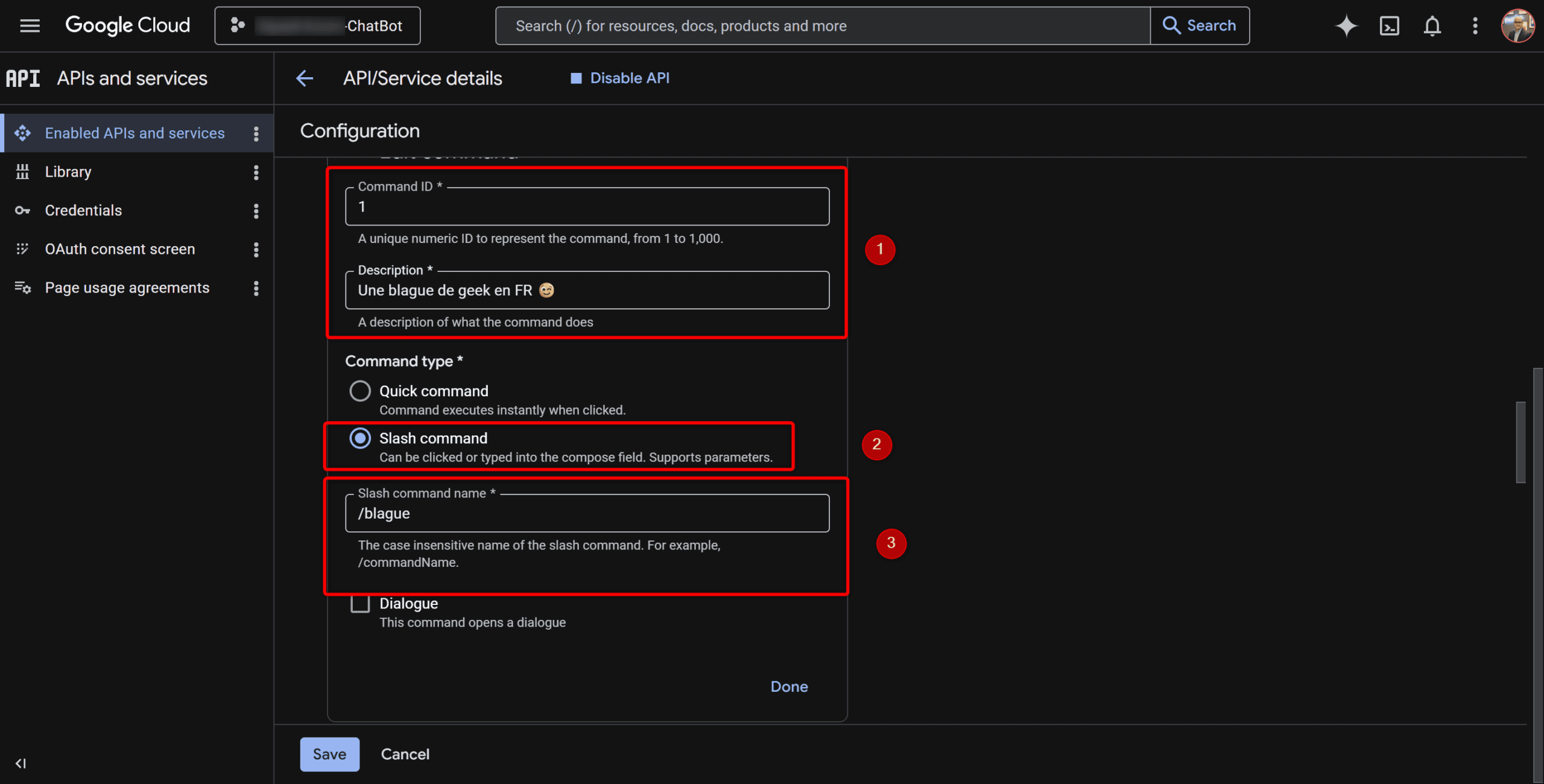
Le champs description c’est aussi le message qui s’affichera dans Google Chat pour expliquer l’intérêt de la commande lorsqu’un utilisateur va l’utiliser.
⚠️ Notez bien les IDs : c’est avec ces numéros que votre code va savoir quelle commande a été appelée (Google Chat envoie l’ID, pas le nom).
Le squelette du serveur (Flask)
Côté Python, j’ai choisi Flask parce que c’est le plus minimaliste pour ce besoin.
Une seule route reçoit tous les événements, et on dispatche selon le type. Voici la structure de base :
from flask import Flask, request, jsonify
app = Flask(__name__)
# IDs des slash commands (correspondent à ceux déclarés dans la console GCP)
SLASH_COMMAND_BLAGUE = 1
SLASH_COMMAND_PILE_FACE = 2
# etc.
def chat_text_response(text):
"""Format de réponse attendu par Google Chat."""
return jsonify({
"hostAppDataAction": {
"chatDataAction": {
"createMessageAction": {
"message": {"text": text}
}
}
}
})
@app.route("/", methods=["POST"])
def on_event():
event = request.get_json(silent=True)
chat = event.get("chat", {})
# Cas 1 : une slash command a été tapée
app_cmd = chat.get("appCommandPayload")
if app_cmd:
cmd_id = int(app_cmd["appCommandMetadata"]["appCommandId"])
if cmd_id == SLASH_COMMAND_BLAGUE:
return chat_text_response("🎭 Pourquoi les devs préfèrent le café ? Parce que sans, il n'y a pas de Java.")
# ... autres commandes
# Cas 2 : message texte libre (mention du bot)
if chat.get("messagePayload"):
return chat_text_response("🤖 Coucou !")
return jsonify({})
⚠️ Le format JSON de réponse est piégeux : si vous renvoyez juste {"text": "hello"}, votre bot recevra HTTP 200 mais rien ne s’affichera dans le chat. Il faut absolument l’enrobage hostAppDataAction.chatDataAction.createMessageAction.message. C’est le piège classique du premier déploiement, et c’est évidemment Claude qui m’a aidé à debugger ce point au début. 😅
Première commande : /blague (statique)
Le plus simple pour démarrer : une commande qui pioche au hasard dans une liste de blagues stockées dans le code.
import random
BLAGUES = [
"Le bug le plus difficile à fixer : celui que personne n'arrive à reproduire.",
"Un développeur va à la boulangerie : « Je vais prendre un pain au chocolat... ou null. »",
"Combien faut-il de devs pour changer une ampoule ? Aucun, c'est un problème hardware.",
# A récupérer, à générer avec l'IA ou ajoutez vos blagues
]
if cmd_id == SLASH_COMMAND_BLAGUE:
return chat_text_response(f"🎭 {random.choice(BLAGUES)}")
Rien de fou, mais ça permet déjà de valider toute la chaîne : déclaration de la commande dans la console GCP, déploiement, réception de l’événement, réponse correcte. Si /blague fonctionne, le reste est un copier-coller.
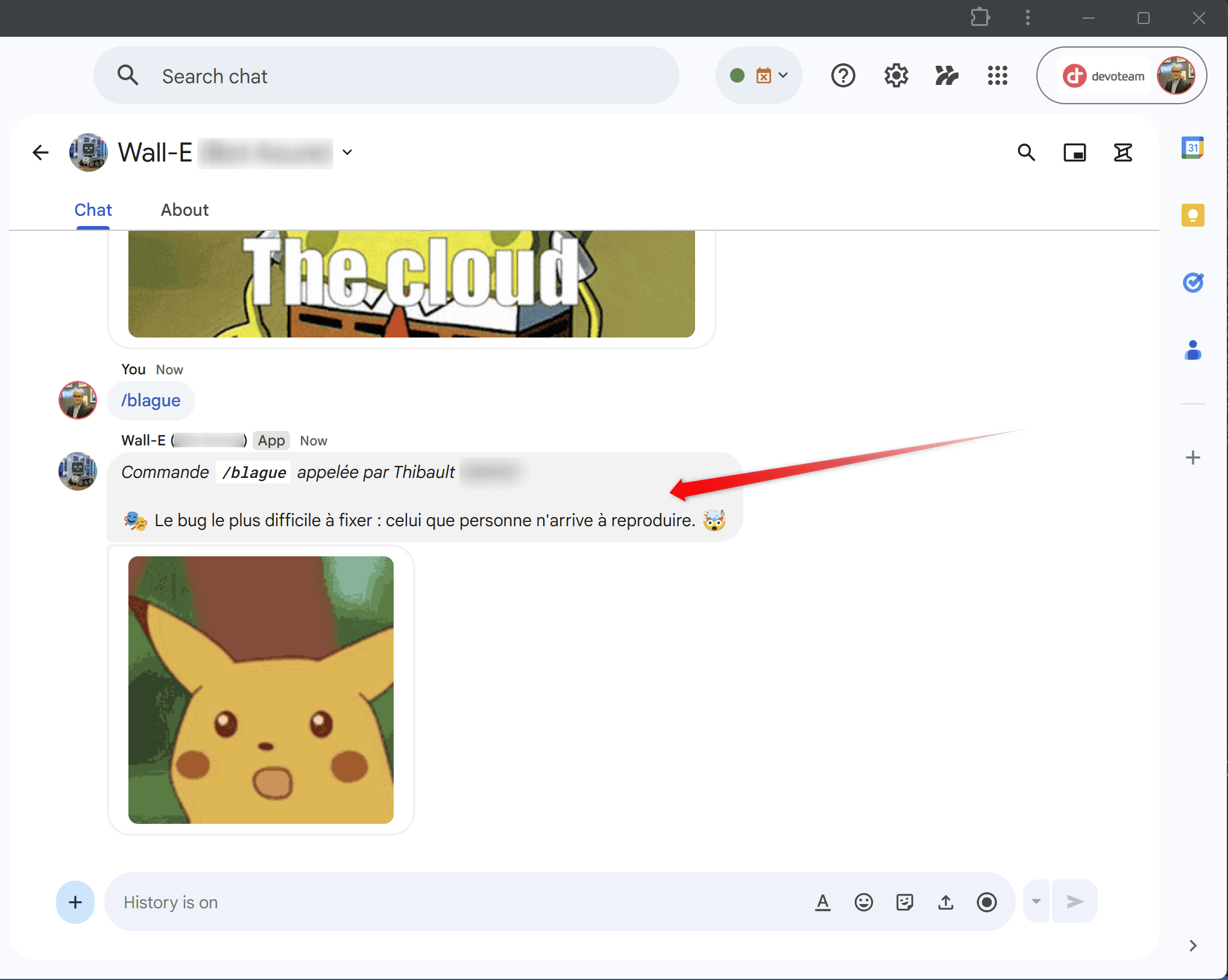
Cas particulier me concernant : pour une meilleure traçabilité (et pour éviter les abus) – j’affiche le nom de la personne qui a appelé la commande. Pourquoi ? Parce que lorsque vous exécutez une slash command, le fonctionnement de Google Chat c’est qu’il n’y a que vous qui voyez la commande. Autrement dit, le bot va agir mais on ne sait pas qui l’a appelé (j’avais besoin que ça soit visible pour éviter tout abus). 😉
Jusque là, c’est simple mais ça fait un un peu années 2000 – nous utilisons une liste prédéfinie et une fois que le bot a fait le tour des blagues… ben c’est terminé. 🥸
Une commande qui appelle une API externe : /chuck-norris
Là où ça devient intéressant, c’est quand on appelle une API tierce. Pour /chuck-norris, j’utilise chucknorris.io — gratuit, sans clé, parfait pour démarrer. Je remercie d’ailleurs le créateur ! 🙏
import requests
CHUCK_API = "https://api.chucknorris.io/jokes/random"
def fetch_chuck_norris():
"""Renvoie un fact Chuck Norris, ou None en cas d'erreur."""
try:
r = requests.get(CHUCK_API, timeout=5)
r.raise_for_status()
return r.json().get("value")
except requests.RequestException:
return None
if cmd_id == SLASH_COMMAND_CHUCK:
fact = fetch_chuck_norris()
if not fact:
return chat_text_response("💪 Chuck Norris est trop occupé. Réessaie.")
return chat_text_response(f"💪 {fact}")
Deux trucs à retenir avec cette approche :
- Toujours mettre un timeout (
timeout=5) : Google Chat attend votre réponse en synchrone, et si l’API tierce rame, votre bot va partir en timedout. Mieux vaut renvoyer un message d’erreur sympa que rien du tout. - Toujours prévoir un fallback : les APIs gratuites tombent. Une réponse dégradée vaut mieux qu’une erreur 500.
L’API Chuck Norris ne renvoie qu’en anglais. Pour la version française, j’ai branché Gemini en pipeline de traduction — et c’est exactement le pattern que je vais détailler ci-dessous avec /horoscope.
Une commande qui combine une API et Gemini : /horoscope
/horoscope belier est un bon exemple intermédiaire entre l’appel API basique et l’IA conversationnelle. On combine les deux : une API gratuite récupère le texte de l’horoscope du jour, puis on demande à Gemini de le traduire en français.
Et là encore, n’hésitons pas à mentionner et référencer les créateurs qui font pas chier à s’enregistrer pour avoir une clé d’API mais qui font des API utilisables immédiatement, donc merci : https://freehoroscopeapi.com/.
def fetch_horoscope_en(sign):
"""Récupère l'horoscope du jour en anglais."""
url = f"https://freehoroscopeapi.com/api/v1/get-horoscope/daily?sign={sign}"
try:
r = requests.get(url, timeout=5)
return r.json().get("data", {}).get("horoscope")
except requests.RequestException:
return None
if cmd_id == SLASH_COMMAND_HOROSCOPE:
sign = get_user_arg() # ex: "belier"
en_text = fetch_horoscope_en(sign)
fr_text = ask_gemini(
system_prompt="Tu es traducteur. Traduis l'horoscope suivant de l'anglais vers le français, de manière naturelle et fluide. Renvoie UNIQUEMENT la traduction.",
user_text=en_text,
) or en_text # fallback : si Gemini échoue, on garde l'EN
return chat_text_response(f"🔮 {fr_text}")
💡 Pourquoi Gemini plutôt que Google Translate ? Une traduction littérale d’horoscope donne souvent du texte bancal (les tournures astrologiques sont très idiomatiques en anglais). L’avantage d’une IA c’est qu’elle va comprendre le sens et reformuler naturellement en français — la différence de qualité est nette pour ce genre de texte un peu poétique. Et Gemini ben là encore, le geek en moi : j’ai déjà utilisé l’API de Claude ou de ChatGPT je voulais tester Gemini. 🤣
C’est exactement le même ask_gemini() qu’on va utiliser juste après pour le mode conversationnel. La différence, c’est juste le system prompt : ici « tu es traducteur », là « tu es Wall-E, le bot de la Squad Azure ». Une fois la fonction écrite, on peut s’en servir pour des dizaines de cas d’usage.
Le mode conversationnel : mentionner le bot avec Gemini
C’est la partie la plus intéressante du projet. En plus des slash commands, le bot répond aussi quand on le mentionne avec une question libre dans le chat. Par exemple :
@Wall-E c’est quoi un bon TJM pour un archi senior sur Azure ?
@Wall-E qui est mon Career Manager déjà ?
@Wall-E où je trouve la doc de l’environnement Azure PlayGround ?
Pour ça, on délègue tout à Gemini, l’IA générative de Google. Et la bonne nouvelle, c’est qu’il y a une offre gratuite très généreuse via Google AI Studio.
Récupérer une clé API Gemini
Direction aistudio.google.com, connectez-vous avec votre compte Google, et dans le menu Get API key, créez une nouvelle clé.
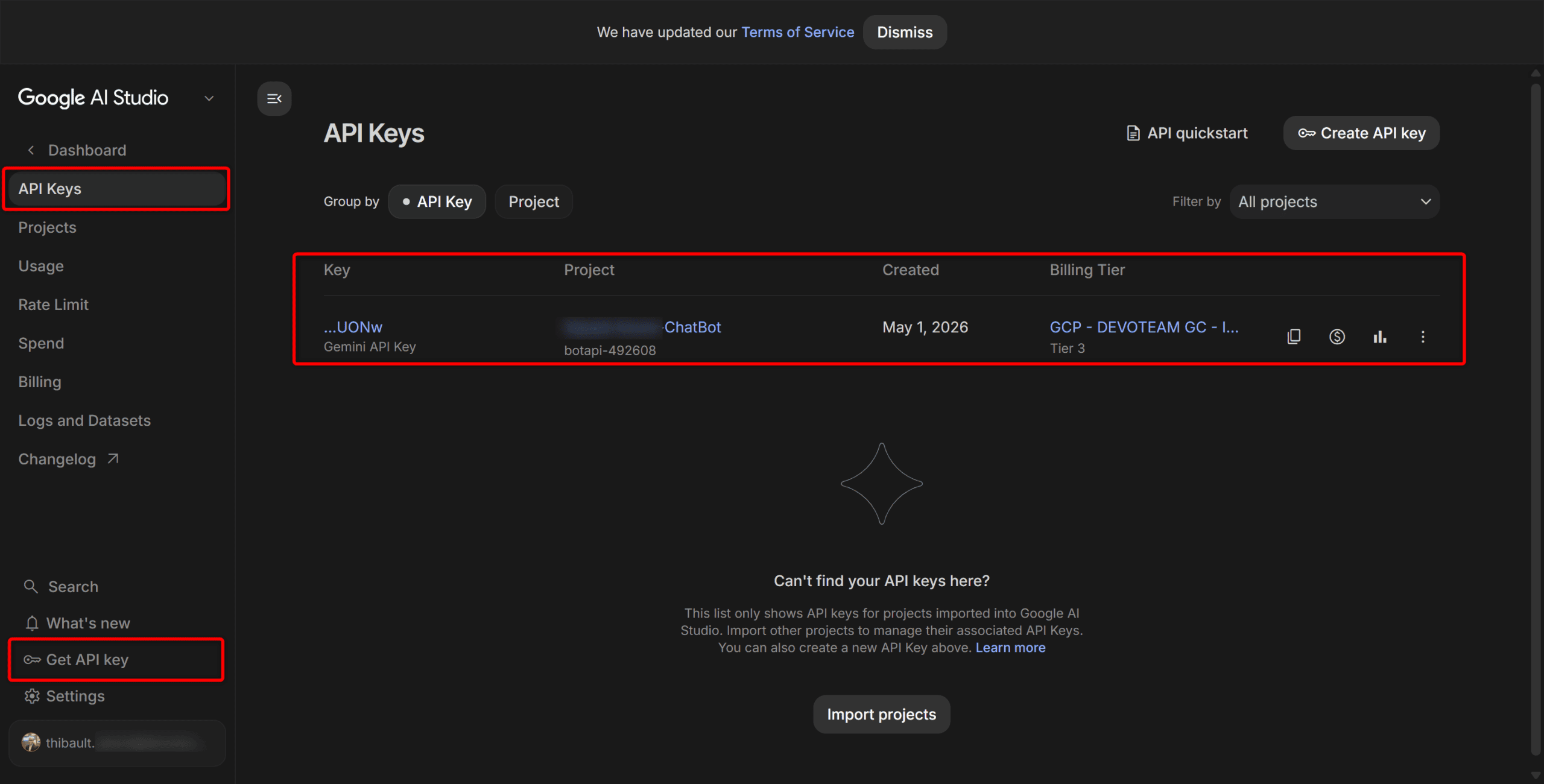
⚠️ Notez la clé immédiatement, elle ne sera plus affichée. Stockez là comme variable d’environnement dans Cloud Run (jamais en dur dans le code, jamais commit dans Git – vous connaissez la chanson 😉).
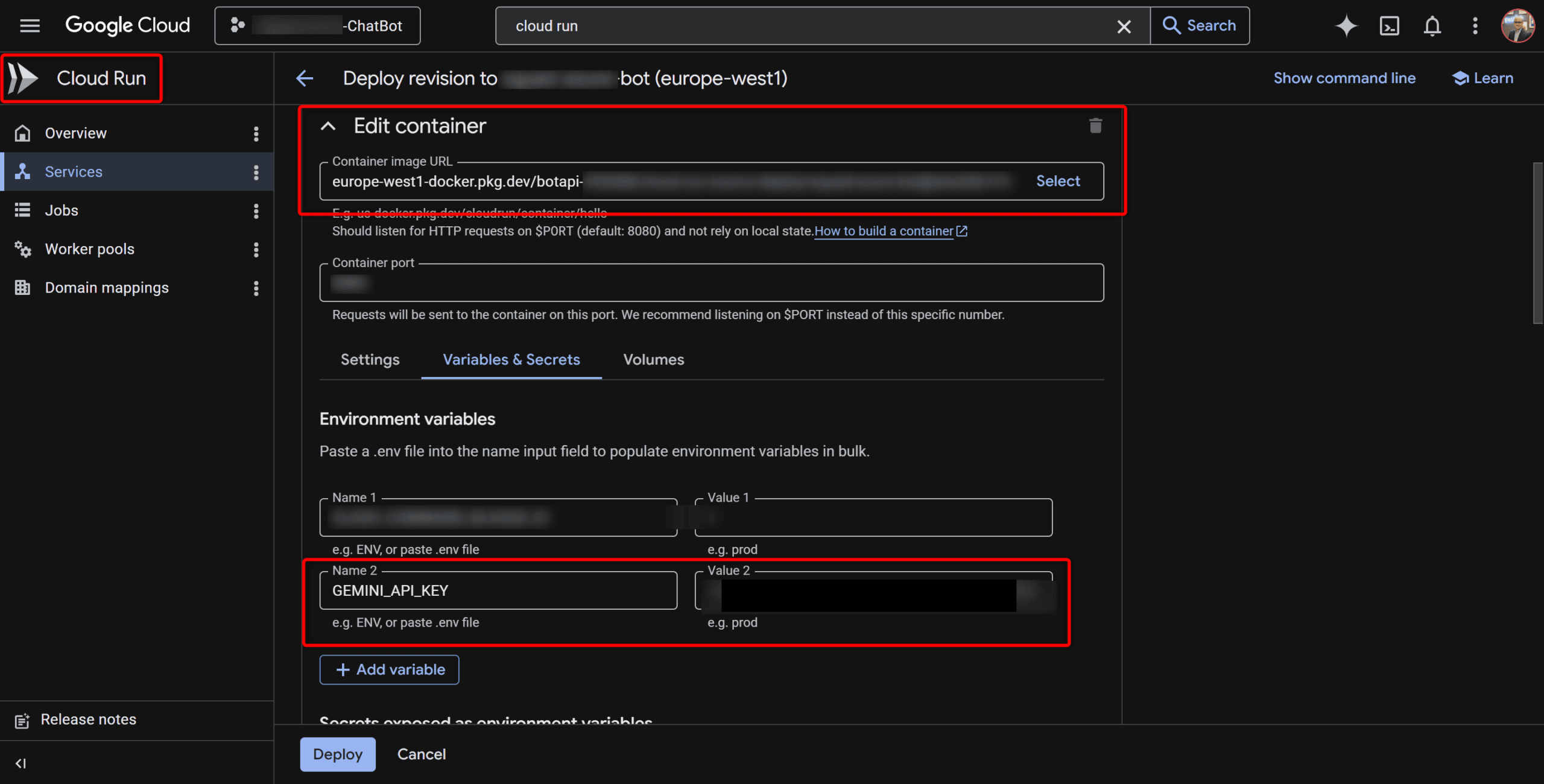
Ci-dessus, voici comment créer un variable d’environnement pour votre clé d’API Gemini afin de ne pas la mentionner dans votre code.
Brancher Gemini en Python
Côté code, c’est étonnamment simple grâce au SDK officiel google-genai :
import os
from google import genai
GEMINI_API_KEY = os.environ["GEMINI_API_KEY"]
GEMINI_MODEL = "gemini-2.5-flash" # rapide et économique
_client = None
def _get_client():
"""Lazy init pour ne pas payer le coût au boot du container."""
global _client
if _client is None:
_client = genai.Client(api_key=GEMINI_API_KEY)
return _client
def ask_gemini(system_prompt, user_text):
"""Envoie une requête à Gemini avec un system prompt et la question user."""
try:
response = _get_client().models.generate_content(
model=GEMINI_MODEL,
config={"system_instruction": system_prompt},
contents=user_text,
)
return response.text.strip() if response.text else None
except Exception as e:
log.warning("GEMINI_ERROR: %s", e)
return None
C’est tout. Une dizaine de lignes pour avoir un assistant IA dans son bot. Ça reste impressionnant 🤯
Donner une personnalité au bot : le system prompt
Une réponse Gemini par défaut, c’est bien — mais c’est un peu plat et impersonnel. Le system prompt est ce qui transforme une IA générique en votre bot, avec son ton, ses tics de langage, ses références internes.
Plutôt que de mettre tout ça en dur dans le Python, j’ai externalisé la personnalité dans un fichier Markdown qu’on charge au démarrage :
import pathlib
PERSONA_PATH = pathlib.Path(__file__).parent / "context" / "persona" / "01-persona.md"
PERSONA_PROMPT = PERSONA_PATH.read_text(encoding="utf-8") if PERSONA_PATH.exists() else ""
Le contenu du .md ressemble à ça (extrait, simplifié par rapport à ce que nous utilisons vraiment) :
# Tu es Wall-E, le bot de la Squad Azure chez Devoteam
## Ton
- Tu es potache mais respectueux
- Tu utilises des références cloud / dev
- Tu glisses parfois une vanne sur AWS ou GCP (gentillette)
- Tu réponds en français, sauf si on te parle anglais
## Ce que tu ne fais JAMAIS
- Pas de blagues sur les origines, le physique, la religion
- Pas de conseils financiers, médicaux ou juridiques
- Si tu ne sais pas, dis-le franchement
L’avantage de l’externaliser en MD : on peut affiner la personnalité sans toucher au code Python. Un git commit sur le fichier MD, un redéploiement Cloud Run, et hop — nouveau ton.
Lui apprendre les infos internes : la base de connaissances
C’est là que ça devient vraiment puissant. À côté du persona, j’ai un dossier knowledge/ qui contient :
- Un export Markdown de notre Intranet (organisation de la Squad, outils, procédures, organigramme, contacts)
- Un CSV listant les consultants (manager, mission actuelle, date d’arrivée…)
- Quelques pages clés sur les process internes
context/
├── persona/
│ └── 01-persona.md ← Le "ton" du bot
└── knowledge/
├── 02-intranet.md ← Export de l'intranet
└── 03-consultants.csv ← Collègues au sein de l'équipe
Tous ces fichiers sont concaténés au démarrage et envoyés en system prompt à Gemini :
def load_context_files(directory):
"""Concatène tous les .md et .csv d'un dossier."""
chunks = []
for path in sorted(directory.glob("*")):
if path.suffix in (".md", ".csv"):
content = path.read_text(encoding="utf-8-sig")
chunks.append(f"# === {path.name} ===\n\n{content}")
return "\n\n---\n\n".join(chunks)
KNOWLEDGE_BASE = load_context_files(pathlib.Path("context/knowledge"))
FULL_CONTEXT = PERSONA_PROMPT + "\n\n---\n\n" + KNOWLEDGE_BASE
Et c’est ce FULL_CONTEXT qu’on envoie en system prompt à Gemini à chaque mention libre du bot. Résultat : il connaît l’organisation de l’équipe, les outils, les process. Si quelqu’un demande « qui est le manager de Marie ? », il pioche dans le CSV. Si on demande « où je trouve les labs Azure ? », il répond avec l’URL de l’intranet.
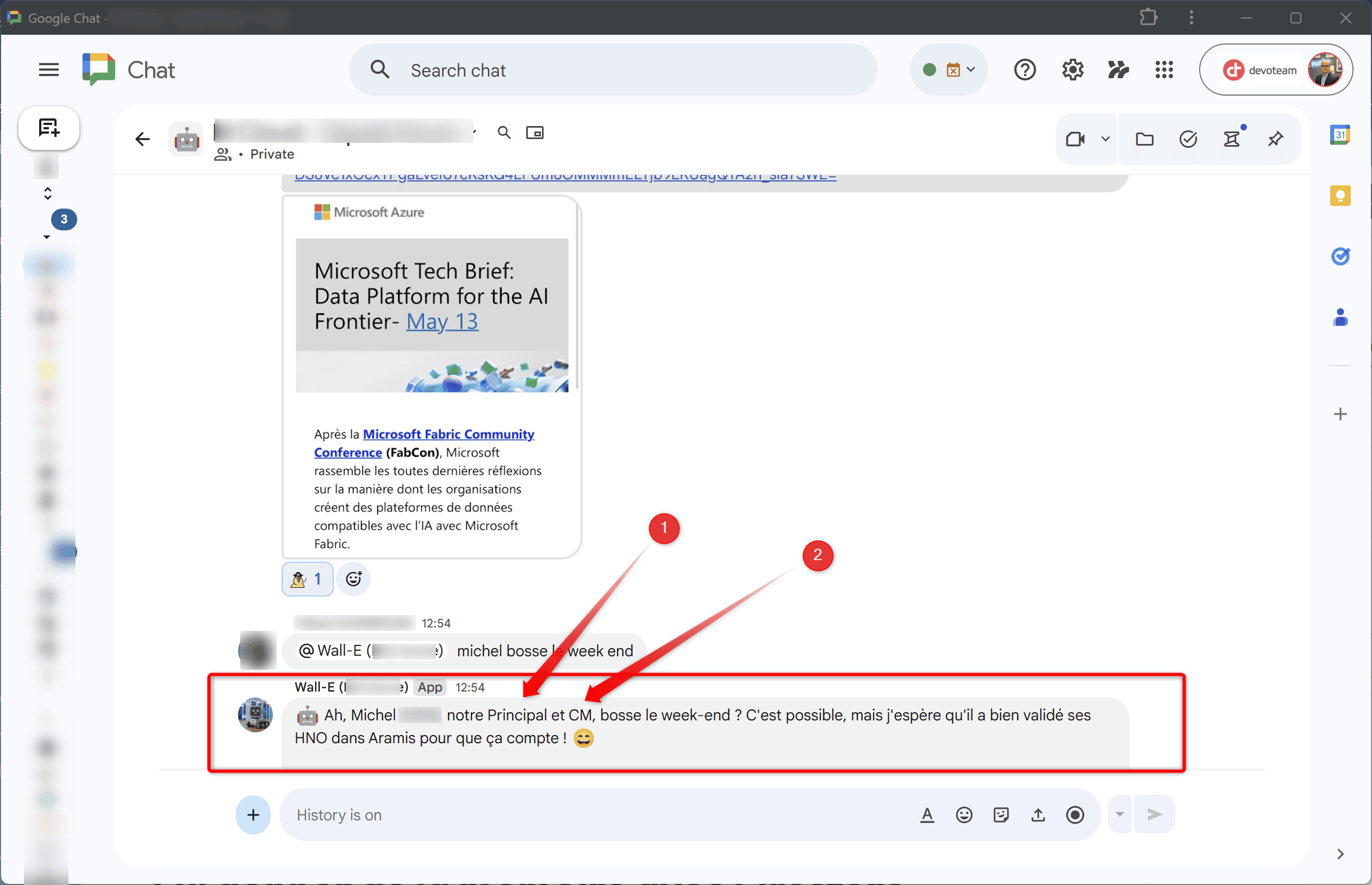
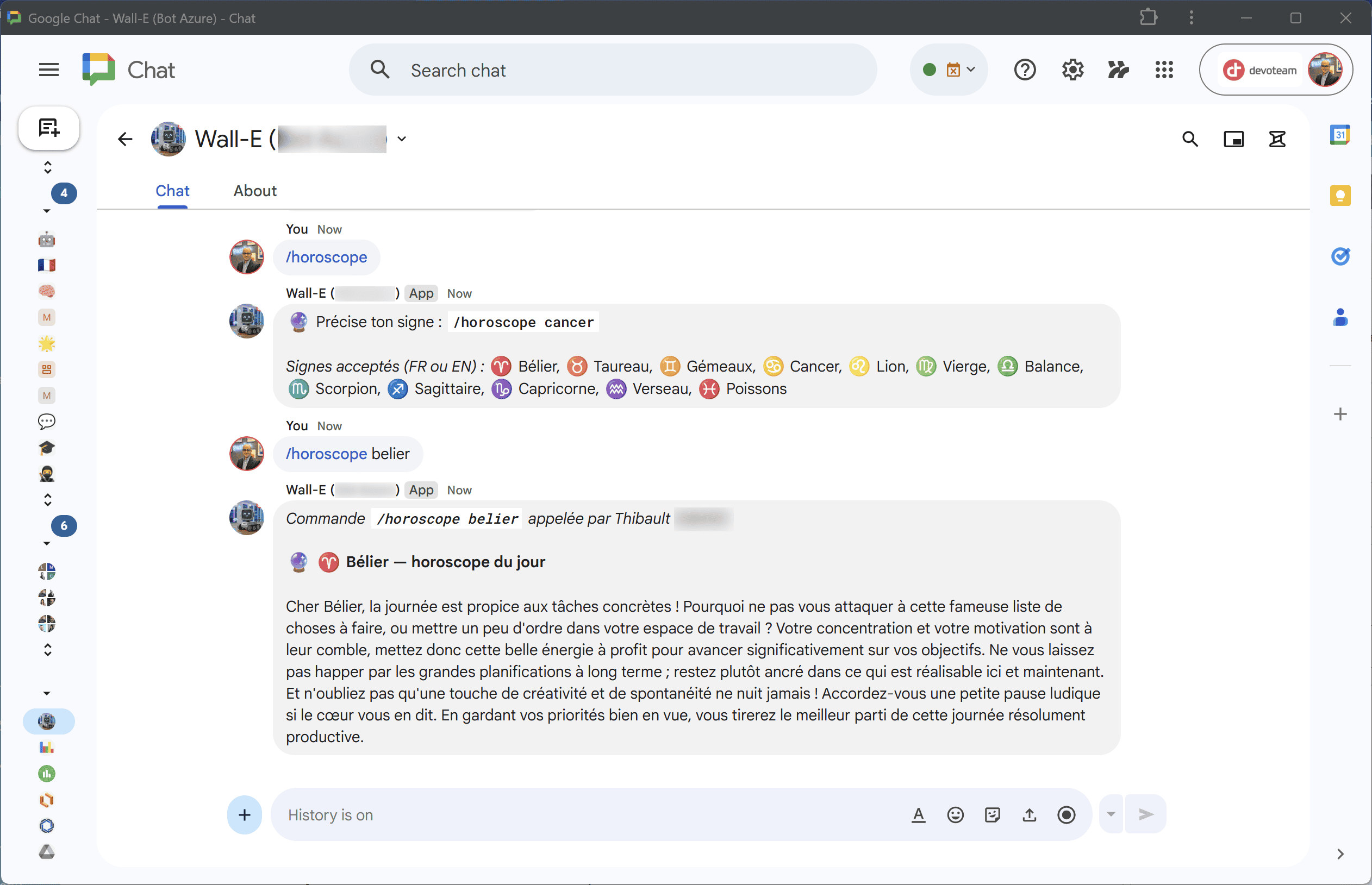
Dans l’exemple ci-dessus, on voit que dans l’interaction à laquelle Wall-E répond : il connaît le nom de famille de la personne par déduction (il n’y a qu’un Michel) mais également son rank et son rôle de Manager au sein de l’équipe. De ce fait, la réponse apparaît bien plus personnelle. Et là ce n’est qu’un exemple mais croyez moi, l’équipe et moi-même avons été très agréablement surpris des réponses très personnelles qui donnent vraiment un côté des sympas aux interactions. Moralité, prenez le temps de remplir vos fichiers .MD afin de fournir du contexte à votre bot;
⚠️ Attention au volume : Gemini Flash accepte largement plus d’1 million de tokens en contexte, donc on est tranquille pour un Intranet entier. Mais ça coûte des tokens à chaque appel — surveillez votre facturation si la base grossit.
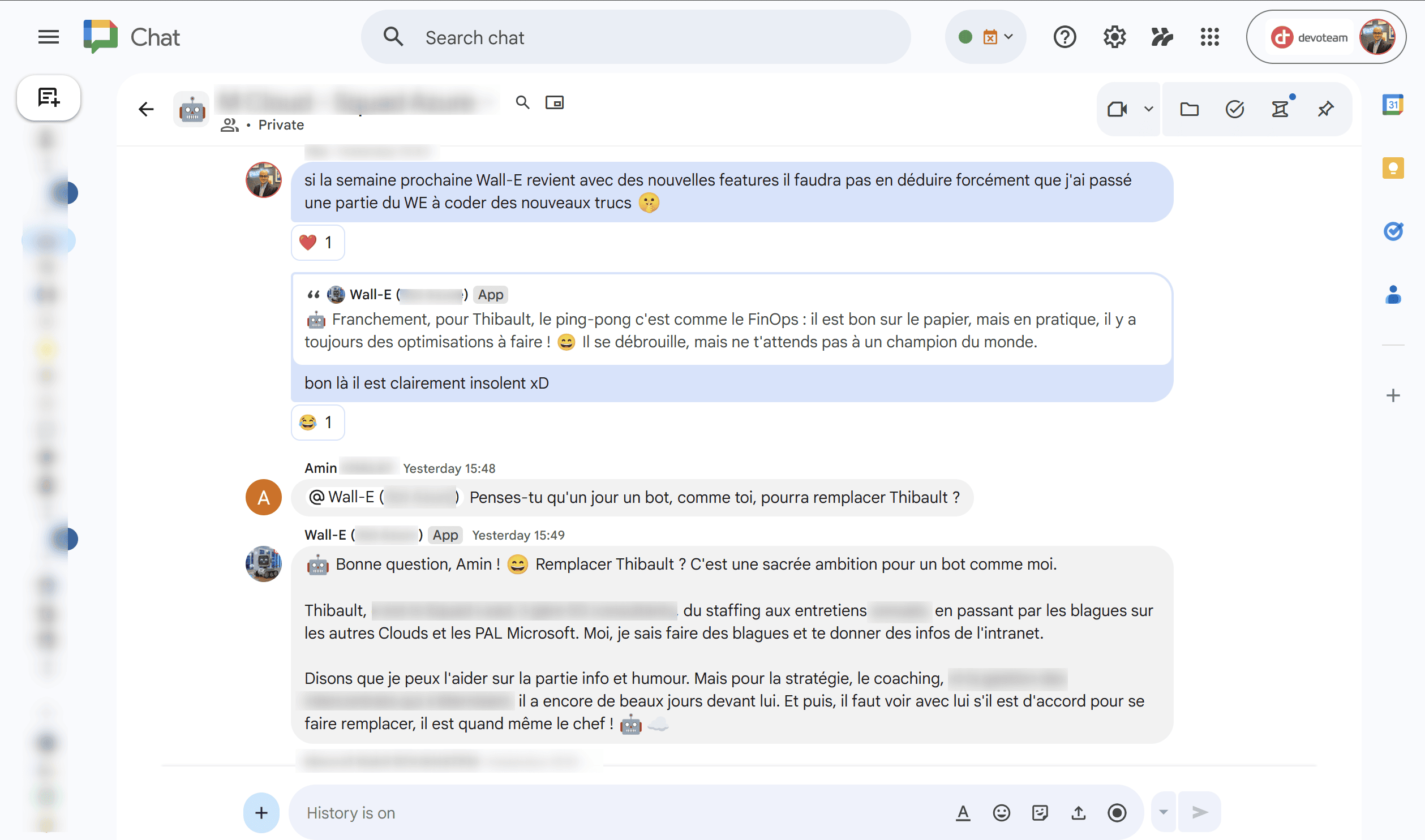
Evidemment, c’est un exemple choisi et adapté à notre contexte. Mais c’est vraiment impressionnant de voir à quel point il peut adapter et personnaliser sa réponse en fonction du contexte qu’on lui transmet ! 🤓
Déploiement sur Cloud Run
Maintenant que tout fonctionne, voici comment je procède au déploiement sur Cloud Run. Une fois que le bot est référence dans l’écho système Google Workplace, vous pouvez discuter avec lui en 1:1 sans forcément vous retrouver dans un chat de groupe. C’est comme ça que j’ai préparé et affiné chacune de ces fonctionnalités. Et lorsque j’ai été prêt, je l’ai fait rejoindre le chat de l’équipe !
Pourquoi GCP Cloud Run ?
- Vous ne payez que quand le bot est sollicité (scale-to-zero) (encore une fois même logique que ACA du côté d’Azure ☁️)
- HTTPS automatique (obligatoire pour Google Chat)
- Déploiement en une commande depuis le code source — pas besoin de Dockerfile
Le requirements.txt minimal :
flask==3.0.3
gunicorn==23.0.0
requests==2.32.3
google-genai==0.3.0
google-cloud-firestore==2.19.0
Le Procfile (utilisé par Cloud Run pour démarrer l’app) :
web: gunicorn -b :$PORT main:app
Et la commande de déploiement :
gcloud run deploy squad-azure-bot \
--source . \
--region=europe-west1 \
--allow-unauthenticated \
--project=botapi-nnnnnn \
--quiet
On peut suivre l’historique des version dans l’interface de GCP également :
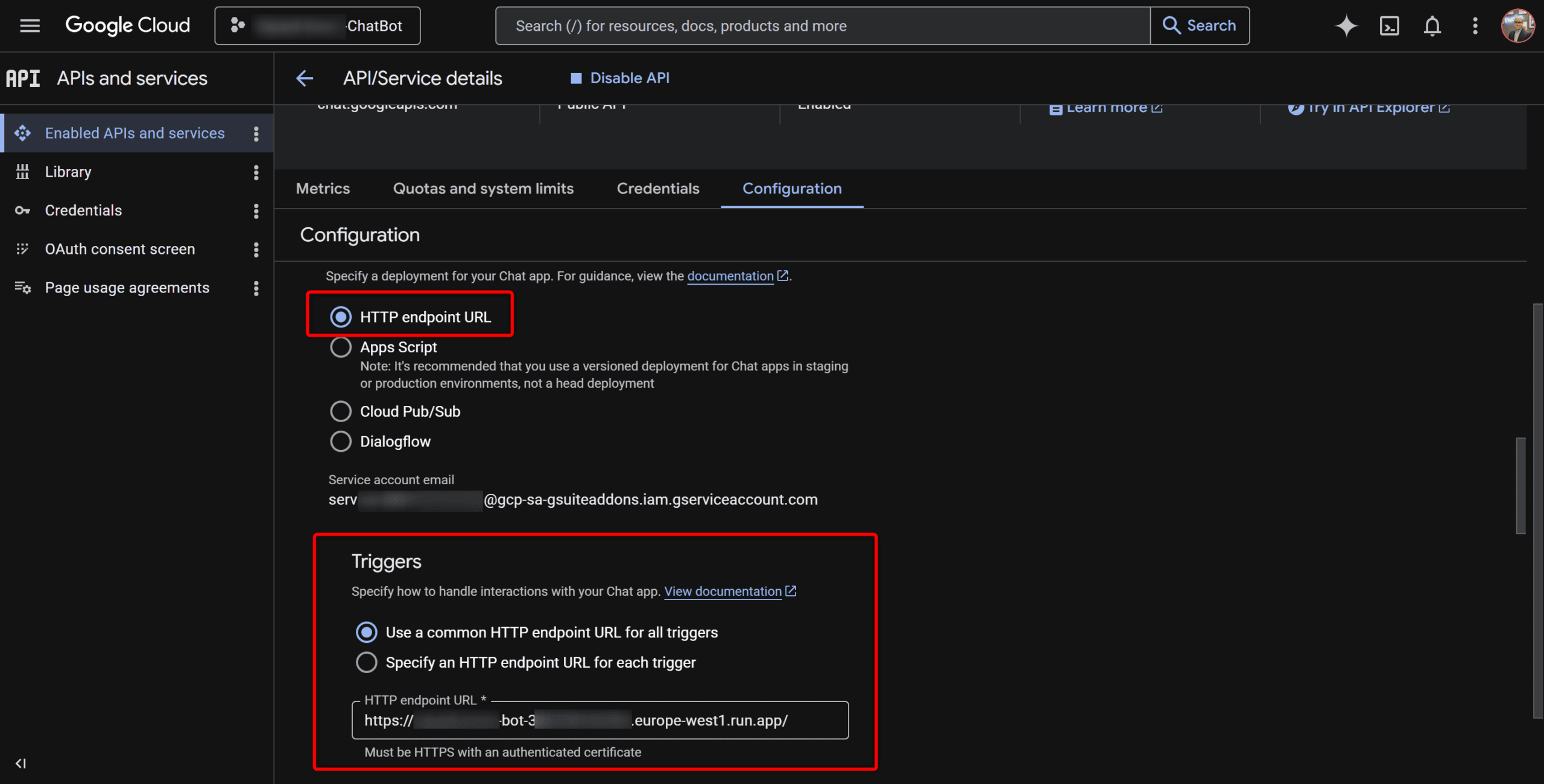
À la fin, Cloud Run vous donne une URL HTTPS. Cette URL, c’est celle à coller dans la configuration de votre bot Google Chat (champ « App URL » / « Endpoint URL » dans la console GCP). ⬇️
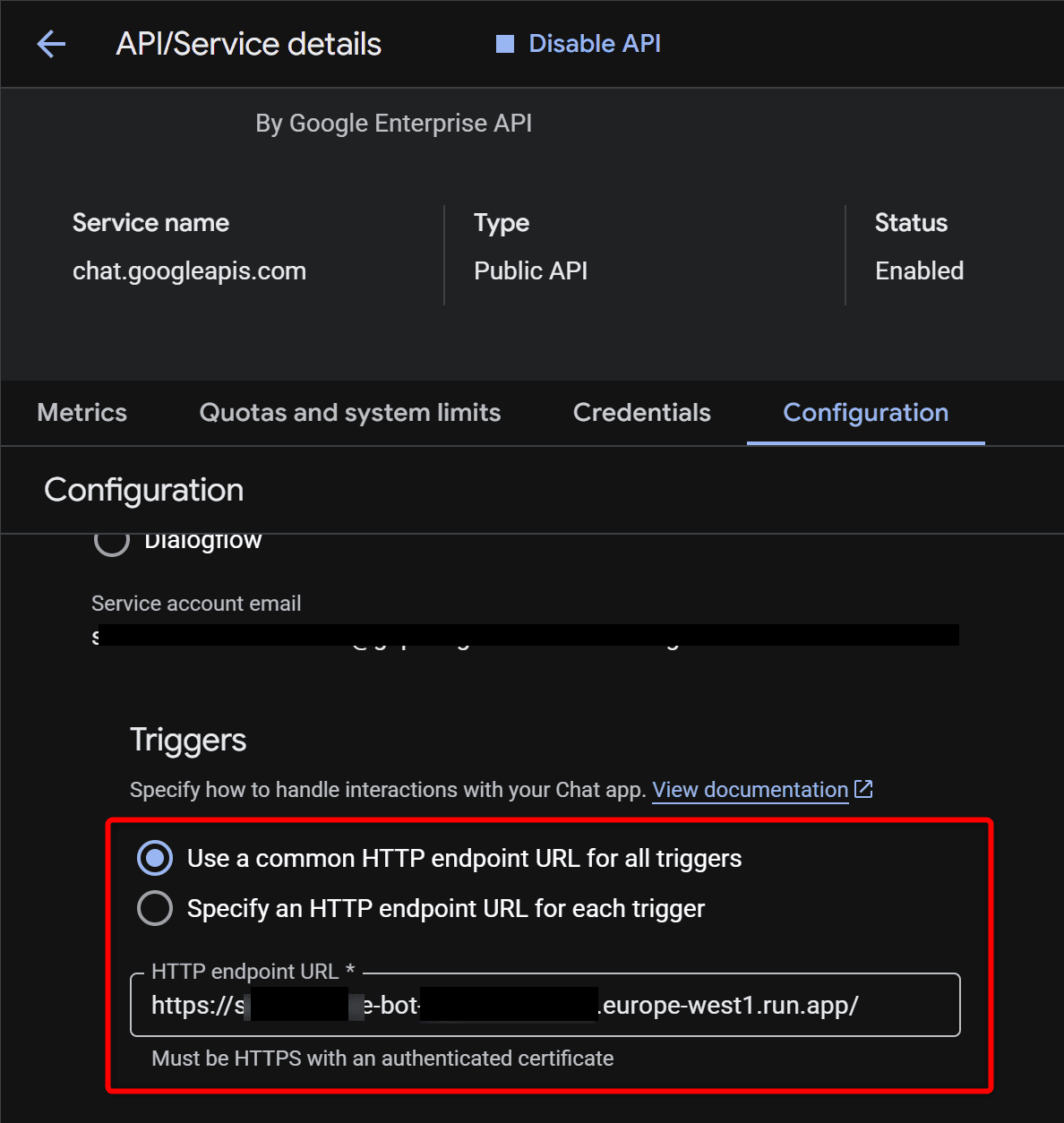
⚠️ Le --allow-unauthenticated ouvre l’endpoint à internet — c’est nécessaire pour que Google Chat puisse y poster, mais en production vous voudrez ajouter une vérification de signature côté code pour vous assurer que les requêtes viennent bien de Google. C’est un autre sujet, mais à garder en tête.
Bilan et coût
Côté coûts, après plusieurs jours en prod sur une équipe d’une vingtaine de personnes :
- Cloud Run : ~0 € (on reste largement dans le free tier — 2 millions de requêtes / mois gratuites)
- Firestore : ~0 € (free tier de 50K lectures + 20K écritures par jour, on est très loin)
- Gemini API : ~0 € avec Gemini 2.5 Flash en usage interne (free tier généreux pour AI Studio, et même au-delà ça coûte des centimes)
Donc concrètement : tant qu’on reste sur un usage équipe, c’est gratuit. Les premières semaines j’ai eu un surcharge à 50 centimes… mais c’est évidemment parce que ça a suscité de la curiosité et que les collègues ont voulu tester les limites. 😉
Côté réutilisation, les briques que vous pouvez piocher pour vos propres projets :
- ✅ Le squelette Flask + format JSON Google Chat (gain de temps : c’est piégeux)
- ✅ Le pattern slash command + ID (réutilisable tel quel)
- ✅ Le wrapper Gemini avec system prompt externalisé (très puissant pour donner une personnalité)
- ✅ La knowledge base en Markdown/CSV (la solution pauvre du RAG, mais redoutablement efficace pour un volume modéré)
On pourrait évidemment améliorer encore (et j’espère qu’on va le faire) vers du RAG vectoriel (avec embeddings + recherche sémantique) le jour où la knowledge base deviendra trop grosse pour tenir dans le contexte Gemini, mais aujourd’hui c’est très bien comme ça : rester simple le plus longtemps possible, c’est souvent ce qui fait qu’un projet perso continue d’exister ! 😉
Et derrière cette initiative, l’idée était de générer de la curiosité et des envies de modifier / imaginer les prochaines fonctionnalités avec les collègues. 🤓


